|
display_clientdataset_xml - John COLIBRI. |
- mots clé:affichage du contenu d'un tClientDataset - dbExpress - MyBase - format .XML - analyseur lexical et syntaxique - encapsulation de tStringList
- logiciel utilisé: Windows XP, Delphi 6.0
- matériel utilisé: Pentium 1400Mhz, 256 M de mémoire
- champ d'application: Delphi 1 à 6 sur Windows, Kylix
- niveau: utilisateur de tClientDataset
- plan:
1 - Introduction Nous allons présenter ici un utilitaire qui affiche le contenu d'un
tClientDataset. Un tClientDataset est un composant qui gère des données sous forme de table en mémoire. Ces données peuvent provenir: - soit d'une création par code
- soit d'un Serveur de bases de données (Oracle, Interbase, MySql, Sql Serveur...)
- soit d'un fichier disque ayant un format particulier
Ce composant permet la "gestion nomade" de tables:
- l'utilisateur récupère des données du Serveur distant le matin sur son portable
- sauve ces données sur son disque dans un fichier
- chez ses clients, il rallume son portable, recharge les données, effectue
des modification (ajout, effacement, modification) et sauvegarde ses données sur disque
- le soir, de retour au bureau, il recharge les données et met à jour le Serveur distant
Le composant permet aussi de gérer des tables indépendantes sans avoir à utiliser aucun moteur de base de données (le tClientDataset sait sauver et relire des données dans un fichier disque local).
Ce qui nous intéresse ici est l'affichage du contenu des données d'un tClientDataset.
2 - Principe du stockage 2.1 - Analyse mémoire et Analyse disque
Le tClientDataset stocke les lignes de la Table dans une structure mémoire. Le source de tClientDataset n'a pas été publié par Borland. Lorsque Kylix et
Delphi 6 ont été lancés, j'ai beaucoup travaillé sur la toute nouvelle architecture dbExpress dont le tClientDataset est un des composants essentiels. J'avais alors analysé le contenu mémoire en utilisant des dumps
directs de la mémoire (les INTERFACE permettent de récupérer l'adresse de l'objet et donc en analysant la mémoire il est possible de retrouver la structure). Ces techniques permettaient aussi d'analyser les paquets de données
échangées entre le tClientDataset et le DatasetProvider (envoi du schéma et des contraintes, envoi des données, envoi des mises à jour, envoi de la liste des erreurs). Il existe toutefois une façon plus simple d'analyse des données d'un
tClientDataset: il suffit de sauvegarder ses donnée sur disque et d'analyser les données sur disque. Le format n'est bien sur pas identique (en mémoire, les données sont sous forme de colonnes, sur disque, elles sont sous forme de
lignes). Mais puisque le tClientDataset sait relire les données du disque sans perte de substance, l'analyse des données du fichier fournit une image fidèle de ce que contient les données en mémoire.
2.2 - Intérêt
Quel intérêt y a-t-il à analyser les données d'un tClientDataset ? Eh bien, comparé à des Tables relationnelles, ce composant a un comportement très "riche": il peut annuler entièrement ou partiellement des modifications
effectuées auparavant, utiliser des clones etc. La bonne connaissance du contenu des données facilite alors grandement l'apprentissage et la compréhension du fonctionnement du tClientDataset.
2.3 - Les formats disques
Le tClientDataset peut être sauvegardé sur disque sous format binaire ou .XML. Nous allons analyser le format .XML qui est plus simple à présenter.
3 - Création du fichier .XML
3.1 - Création des données La création d'une nouvelle table est très simple: - nous définissons chaque champ en appelant:
FieldDefs.Add - la table est créée par
CreateDataset - nous ajoutons des données par
AppendRecord
Par conséquent:  |
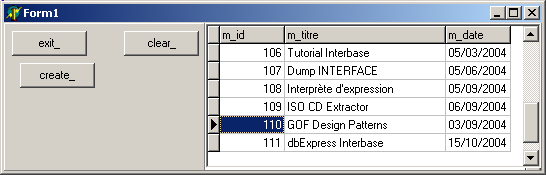
créez une nouvelle application et appelez-la "display_cds_xml" | | | sélectionnez dans la page "dbExpress" de la Palette le composant ClientDataset:
et posez-le sur la tForm | |
| sélectionnez dans la page "Data Access" de la Palette le composant DataSource: et: - posez-le sur la tForm
- sélectionnez sa propriété DataSet et placez-y ClientDataset1
|
| | sélectionnez dans la page "Data Control" de la Palette le composant dbGrid: et: - posez-le sur la tForm
- sélectionnez sa propriété DataSource et placez-y DataSource1
|
| | placez un tButton "create_" sur la Forme et créez sa méthode OnClick. Placez-y les instructions de création des données de ClientDataset. Dans
notre cas nous créons une table contenant quelques articles de ce site:
procedure TForm1.create_Click(Sender: TObject);
begin
with ClientDataset1 do
begin
Close;
FieldDefs.Clear;
with FieldDefs do
begin
Add('m_id', ftInteger, 0);
Add('m_titre', ftString, 20);
Add('m_date', ftDate, 0);
end; // with FieldDefs
CreateDataSet;
AppendRecord([1, 'Site Editor', '1/9/2001']);
AppendRecord([1, 'Pascal To Html', '1/10/2001']);
AppendRecord([1, 'Blobs Interbase', '2/1/2002']);
AppendRecord([1, 'CGI Form', '1/9/2002']);
AppendRecord([1, 'Find USES', '5/6/2003']);
AppendRecord([1, 'Tutorial Interbase', '5/3/2004']);
AppendRecord([1, 'Dump INTERFACE', '5/6/2004']);
AppendRecord([1, 'Interprète d''expression', '5/9/2004']);
AppendRecord([1, 'ISO CD Extractor', '6/9/2004']);
AppendRecord([1, 'GOF Design Patterns', '3/9/2004']);
AppendRecord([1, 'dbExpress Interbase', '15/10/2004']);
Open;
end; // with ClientDataset1
end; // create_Click
| | |
| compilez, exécutez, et cliquez le bouton:
|
Pour sauvegarder les données:
Nous pouvons examiner le contenu du fichier .XML en cliquant sur ce fichier dans un Explorateur Windows: comme .XML est associé à Internet Explorer (ou tout autre Browser que vous utilisez), nous voyons apparaître les données
contenues dans ce fichier: 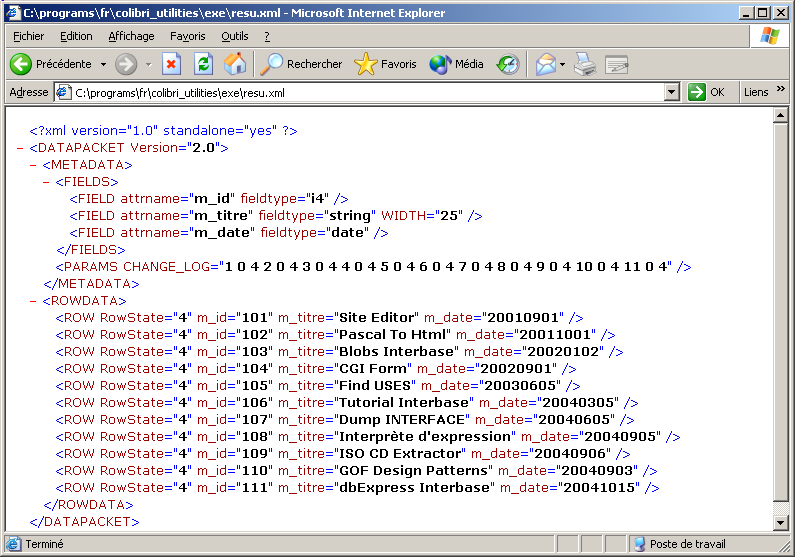
3.2 - Chargement Nous pouvons bien sûr recharger le tClientDataset en utilisant LoadFromFile.
ATTENTION: le format des fichiers utilisés par le tClientDataset est spécial. Vous ne pouvez pas charger n'importe quel .XML dans un tClientDataset. Dans notre cas: |
| sélectionnez dans la page "Data Control" de la Palette le composant FileListBox: et: - posez-le sur la tForm
- sélectionnez sa propriété Mask et placez-y la valeur *.XML
- créez son événement OnClick et chargez les données dans ClientDataset1:
procedure TForm1.FileListBox1Click(Sender: TObject);
var l_file_name: String;
begin
with FileListBox1 do
l_file_name:= Items[ItemIndex];
ClientDataSet1.LoadFromFile(l_file_name);
end; // FileListBox1Click
|
| |
| compilez et exécutez
|  | l'application présente les fichiers .XML disponibles. Cliquez sur l'un
d'entre eux: le ClientDataset charge les données
|
3.3 - Modifications de données Pour nous placer dans le cas d'utilisation général d'un tClientDataset, nous
allons modifier les données qu'il contient. Nous pouvons le faire en tapant dans le dbGrid, mais pour pouvoir répéter les séquences, nous allons utiliser du code: | |
placez un tButton "delete_" sur la Forme et créez sa méthode OnClick. Placez-y les instructions d'effacement de la ligne 4 de ClientDataSet1:
procedure TForm1.delete_5_Click(Sender: TObject);
begin
with ClientDataset1 do
begin
First;
Next; Next; Next; Next;
Delete;
end; // with ClientDataset1
end; // delete_4_Click
| | |
| placez un tButton "append_" sur la Forme et créez sa méthode OnClick. Placez-y les instructions d'ajout d'une ligne à ClientDataSet1:
procedure TForm1.append_Click(Sender: TObject);
begin
with ClientDataset1 do
begin
AppendRecord([112, 'display ClientDataset .XML', '16/10/2004']);
end; // with ClientDataset1
end; // append_Click
| | |
| placez un tButton "modify_interbase_" sur la Forme et créez sa méthode OnClick. Placez-y les instructions qui vont modifier le mois de l'article "Interbase Tutorial":
procedure TForm1.modify_interbase_Click(Sender: TObject);
var l_year, l_month, l_day: Word;
begin
with ClientDataset1 do
begin
if Locate('m_titre', 'Tutorial Interbase', [])
then begin
DecodeDate(FieldByName('m_date').AsDateTime, l_year, l_month, l_day);
Inc(l_month);
if l_month= 13
then begin
l_month:= 1;
Inc(l_year);
end;
Edit;
FieldByName('m_date').AsDateTime:= EncodeDate(l_year, l_month, l_day);
Post;
end;
end; // with ClientDataset1
end; // modify_interbase_Click
| | |
| compilez et exécutez
| Nous allons effectuer les trois types de modifications sur notre tClientDataset:
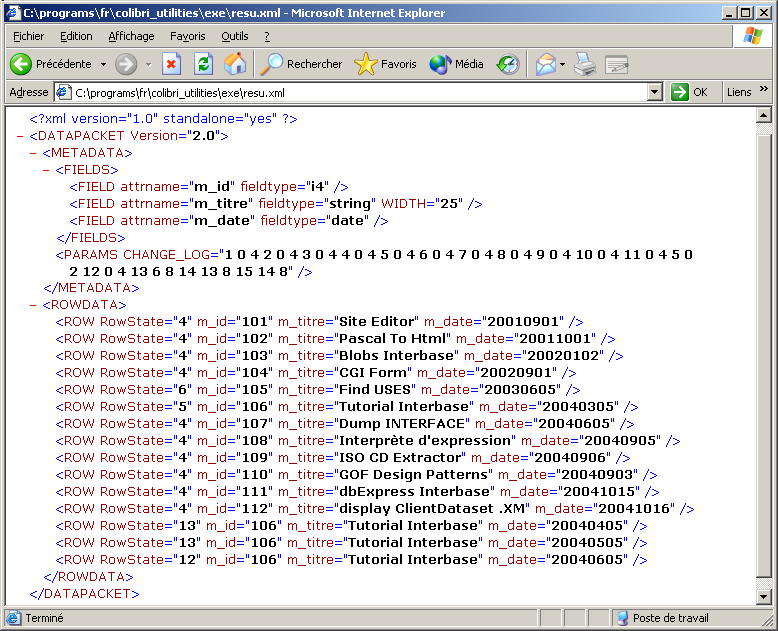
3.4 - Le contenu du fichier En comparant les deux fichiers .XML, il est aisé de voir que:
- le fichier comporte une partie méta-donnée et une partie lignes
- les méta données comportent
- la définition de chaque champ
- le journal des modifications de chaque ligne sous forme de triplets contenant:
- un numéro de ligne (débutant à 1 et, dans notre cas jusqu'à 15)
- le numéro de la version précédente de cette ligne en cas de modification
- un code de changement:
- 4 pour un ajout
- 8 pour une modification
- les lignes sont codées ainsi:
- le nom du champ et sa valeur
- optionnellement, une valeur RowState
Dans notre cas, comme toutes les lignes ont été créée, RowState est
toujours présente. Mais si nous avions importé des données du Serveur Interbase, cette valeur RowState n'est pas présente pour les lignes
importées (cf l'article Interbase dbExpress )
Nous allons à présent construire un utilitaire qui relit ce fichier .XML pour
nous présenter les lignes et leur histoire.
4 - Analyze du fichier .XML 4.1 - Principe Nous allons procéder en deux temps:
- une première unité va analyser le fichier .XML et afficher son contenu en reformatant les lignes
- une seconde unité va contenir une classe qui contient les données de notre
tClientDataset: la liste des lignes et pour chaque ligne, la liste des valeurs
4.2 - Analyse .XML Le fichier est composé essentiellement de balises "< xxx >" et de retours chariot. Les balises sont de plusieurs type:
- les balises "<xxx>" et "</xxx>"
- les balises "<xxx yyyy zzz/>
Et dans chaque balise se trouve - la clé, comme METADATA FIELD ROW etc
- éventuellement des paramètres qui sont au format "nom="valeur""
La classe c_cds_analyze_xml: - charge le fichier dans un tampon mémoire
- analyse chaque élément du fichier en isolant les balises et les retours chariot
- pour les balises:
- si elles contiennent des paramètres, ceux-ci sont extraits
- si la balise est une balise double, nous récursons pour retrouver les balises encapsulées
Voici quelques extraits - la fonction qui extrait les symboles:
function f_get_symbol_recursive: String;
// .. handle_opening_bracket and handle_return
begin // f_get_symbol_recursive
Result:= '';
if m_buffer_index>= m_buffer_size
then exit;
repeat
case m_pt_buffer[m_buffer_index] of
'<' : handle_opening_bracket(l_exit);
chr(13) : handle_return;
else handle_other;
end; // case
until (m_buffer_index>= m_buffer_size) or (Result<> '');
end; // f_get_symbol_recursive
| - la procédure récursive qui analyse les balises:
procedure handle_opening_bracket(var pv_exit: Boolean);
// -- ... here analyze_tag etc
begin // handle_opening_bracket
pv_exit:= False;
// -- skip <
inc(m_buffer_index);
if m_pt_buffer[m_buffer_index]= '/'
then begin
l_slash:= '/';
inc(m_buffer_index);
end
else l_slash:= '';
l_start_index:= m_buffer_index;
repeat
inc(m_buffer_index);
until (m_buffer_index>= m_buffer_size)
or (m_pt_buffer[m_buffer_index] in k_tag_end);
l_length:= m_buffer_index- l_start_index;
if l_length> 0
then begin
l_tag:= f_extract_string_start_end(l_start_index, m_buffer_index- 1);
l_tag:= l_slash+ UpperCase(l_tag);
Result:= l_tag;
// -- get command parameters
if m_pt_buffer[m_buffer_index]<> '>'
then begin
l_parameters:= '';
l_start_index:= m_buffer_index;
repeat
if m_pt_buffer[m_buffer_index]= '"'
then skip_apostroph
else inc(m_buffer_index);
until (m_buffer_index>= m_buffer_size)
or (m_pt_buffer[m_buffer_index] in ['>']);
l_parameters:= f_extract_string_start_end(l_start_index, m_buffer_index- 1);
if l_tag= 'PARAMS'
then analyze_change_log_params(l_parameters);
end; // parameters
// -- skip >
if m_pt_buffer[m_buffer_index]= '>'
then begin
inc(m_buffer_index);
if l_slash= '/'
then Result:= l_tag
else analyze_tag(l_tag, l_parameters);
end
else display('*** could not find >');
end
else begin
l_tag:= '';
display('*** tag is void');
end;
end; // handle_opening_bracket
|
- lorsque la procédure précédente arrive au caractère ">" elle appelle la procédure qui examine le contenu d'une balise:
procedure analyze_tag(p_tag, p_parameters: String);
var l_row_string, l_log_list_string: String;
l_row_index: Integer;
begin
add_line;
if p_tag= 'ROW'
then begin
l_row_string:= f_spaces(l_indentation);
l_row_string:= l_row_string+ IntToStr(l_row_number+ 1);
// -- find if a CHANGE_LOG entry has this number
l_row_index:= l_c_merge_log_line_number_list.IndexOf(IntToStr(l_row_number+ 1));
If l_row_index<> -1
then l_log_list_string:= l_c_merge_log_list[l_row_index]
else l_log_list_string:= '';
l_row_string:= l_row_string+ ' ('+ l_log_list_string+ ') :';
l_row_string:= l_row_string+ ' <'+ p_tag+ p_parameters+ '>';
add(l_row_string);
// -- also add to the c_table structure
if p_c_table<> Nil
then p_c_table.f_c_add_line(l_row_number, l_log_list_string, p_parameters);
Inc(l_row_number);
end
else add(f_spaces(l_indentation)+ '<'+ p_tag+ p_parameters+ '>');
add_line;
if (p_tag<> 'ROW') and (p_tag<> 'FIELD')
then Inc(l_indentation, 2);
add(f_spaces(l_indentation));
// -- recurse
Result:= f_get_symbol_recursive;
if Result<> '/'+ p_tag
then begin
// -- backup
pv_exit:= True;
if (p_tag<> 'ROW') and (p_tag<> 'FIELD')
then Dec(l_indentation, 2);
end
else begin
add_line;
Dec(l_indentation, 2);
// -- ?? assume that the </xxx> has never any params
add(f_spaces(l_indentation)+ '<'+ Result+ '>');
add_line;
add(f_spaces(l_indentation));
// -- look for the next symbol or tag
Result:= f_get_symbol_recursive;
end;
end; // analyze_tag
| Les procédures add_line et add_text ajoute le texte dans une tStringList
appelée m_c_result_list, que nous pouvons réafficher dans le programme appelant. De plus si nous recontrons la balise PARAMS CHANGE_LOG, nous décortiquons les triplets pour pouvoir les placer au début de leur ligne respective.
Incorporons donc ce traitement dans notre programme: | | placez un tButton "analyze_xml_" sur la Forme et créez sa méthode
OnClick. Placez-y les instructions qui appelle l'analyse du fichier:
procedure TForm1.analyze_xml_Click(Sender: TObject);
begin
with c_cds_analyze_xml.create_cds_analyze_xml('xml', 'resu.xml') do
begin
analyze_xml;
display_line;
display_strings(m_c_result_list);
Free;
end; // with c_analyze_xml
end; // analyze_xml_Click
| | |
| compilez et exécutez. Cliquez "analyze_xml_"
| | | le programme affiche:
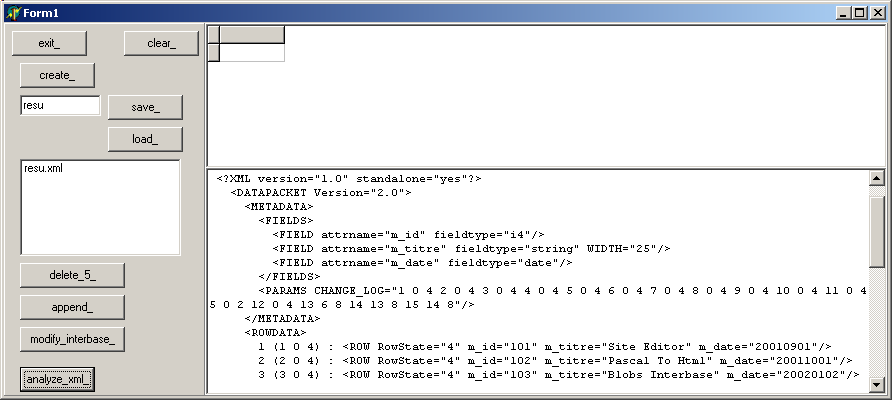 Vous constatez que nous avons bien replacé les triplets en début de chacune des lignes.
|
4.3 - Stockage de la table dans une structure
Nous avons aussi créé une structure qui stocke les données de la table dans une structure de lignes / colonnes. La structure est composée d'une tStringList de lignes, chaque ligne contenant
une tStringList de colonnes, chaque cellule étant un objet (ne contenant dans la version actuelle que le texte contenu dans la cellule). La définition des 3 classes est la suivante:
type
c_column= Class(c_basic_object)
// -- m_name: the content of the cell
Constructor create_column(p_name: String);
Destructor Destroy; Override;
end; // c_column
c_table= Class; // forward
c_line= // one "line"
Class(c_basic_object)
// -- m_name: the parameters of "<ROW ... >"
m_c_parent_table: c_table;
m_c_column_list: tStringList;
m_line_number, m_previous_line_number, m_update_code: Integer;
Constructor create_line(p_name: String;
p_c_parent_table: c_table;
p_line_number, p_previous_line_number, p_update_code: Integer);
function f_column_count: Integer;
function f_c_column(p_column_index: Integer): c_column;
function f_index_of(p_column_name: String): Integer;
function f_c_find_by_column(p_column_name: String): c_column;
procedure add_column(p_column_name: String; p_c_element: c_column);
function f_c_add_column(p_column_name: String): c_column;
procedure display_column_list;
Destructor Destroy; Override;
end; // c_line
c_table= // "line" list
Class(c_basic_object)
m_c_line_list: tStringList;
// -- the header of each column
m_c_column_name_list: tStringList;
Constructor create_table(p_name: String);
function f_line_count: Integer;
function f_c_line(p_line_index: Integer): c_line;
function f_index_of(p_line_name: String): Integer;
function f_c_find_by_line(p_line_name: String): c_line;
procedure add_line(p_line_name: String; p_c_line: c_line);
function f_c_add_line(p_row_number: Integer; p_log_list_string, p_parameters: String): c_line;
procedure display_formatted_line_list;
Destructor Destroy; Override;
end; // c_table
|
Il s'agit donc d'une encapsulation à 2 niveaux d'une tStringList (cf. le squelette d'une tStringlist ).
Nous utilisons cette structure de la façon suivante: - le programme principale crée un objet de type c_table
- cet objet est passé comme paramètre à c_cds_analyze_xml.analyze_xml
- chaque fois que c_cds_analyze_xml.analyze_tag a récupéré une balise, la procédure c_table.f_c_add_line est appelée en fournissant le numéro de la ligne, le triplet, les paramètres
- c_table.f_c_add_line crée alors une nouvelle ligne, puis décompose les paramètres pour en extraire le titre de la colonne et la valeur de la colonne
- c_table peut alors réaliser un affichage formaté:
- les titres des colonnes sont affichés une fois uniquement
- la taille maximale du texte de chaque colonne est calculé
- pour chaque ligne, nous affichons
- son numéro
- les codes de modifications et RowState
- la liste des valeurs
Par conséquent | | placez un tButton "display_table_" sur la Forme et créez sa méthode
OnClick. Placez-y les instructions qui créent une c_table, appelle l'analyse du fichier, et affiche le résultat:
procedure TForm1.display_table_Click(Sender: TObject);
var l_c_table: c_table;
begin
with c_cds_analyze_xml.create_cds_analyze_xml('xml', 'resu.xml') do
begin
l_c_table:= c_table.create_table('table');
analyze_xml(l_c_table);
display_line;
l_c_table.display_formatted_line_list;
l_c_table.Free;
Free;
end; // with c_analyze_xml
end; // display_table_Click
| | |
| compilez et exécutez. Cliquez "display_table_"
| | | le programme affiche:
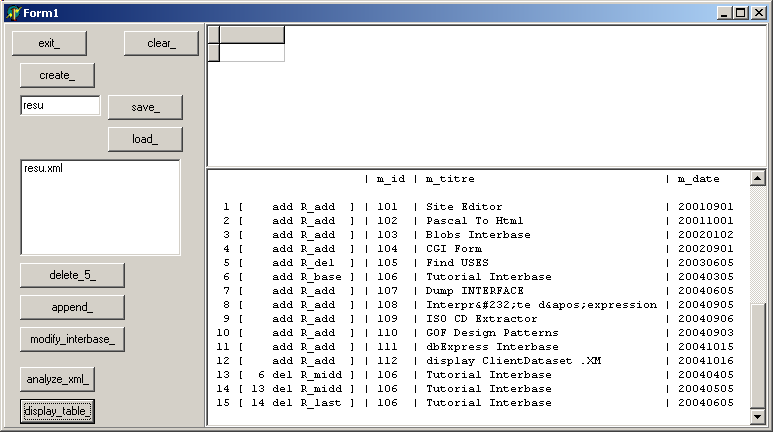
|
Le dernier affichage montre que: - la ligne 5 comporte bien une signature RowState d'effacement
- rien ne distingue l'ajout de la ligne 12 des 11 lignes précédentes chargées depuis le fichier .XML
- les lignes modifiées sont chaînées:
- la ligne 13 désigne la ligne 6
- la ligne 14 désigne la ligne 13
- la ligne 15 désigne la ligne 14
De plus les valeurs de RowState sont différentes pour la ligne originale (6), les lignes intermédiaires (13 et 14) et la dernière valeur connue (15)
5 - Améliorations L'analyze du text .XML date de nos premières explorations de dbExpress / Midas sous Linux. Cela se voit: la récursion semble mal emboîtée. Si je devais
réécrire le programme, je partirais d'une grammaire .XML correspondant aux fichiers Borland, et je laisserais le Con-Compilateur mettre en place l'analyseur syntaxique. Les classes de stockage sont aussi un peu trop grosses. Actuellement nous
pourrions nous passer de la classe c_column. De même, nous avons utilisé des tStringList, alors que des tList auraient suffi. Encore que nous pourrions utiliser les chaînes pour trier les lignes par exemple (chaque enregistrement
et ses versions modifiées pourraient être regroupés). En attendant le programme marche, et il avait surtout été sorti de la naphtaline pour afficher le contenu d'un tClientDataset pour l'article
Interbase dbExpress. Le module qui analysait directement le contenu mémoire d'un tClientDataset et qui nous servait aussi à surveiller les paquets échangés entre un
tDatasetProvider et un tClientDataset n'a pas été publié pour le moment.
6 - Télécharger le source Nous avons placé le projet dans un .ZIP qui comprend:
- le .DPR, la forme principale, les formes annexes éventuelles
- les fichiers de paramètres (le schéma et le batch de création)
- toutes les librairies (Unit) nécessaires (le .ZIP est autonaume)
Ce .ZIP contient des chemins RELATIFS. Par conséquent: - créez un répertoire n'importe où sur votre machine
- placez le .ZIP dans ce répertoire
- dézippez et les sous-répertoires nécessaires seront créés
- compilez et exécutez
Au niveau sécurité: - le .ZIP:
- ne modifie pas votre PC (pas de changement de la Base de Registre, d'écrasement de DLL ou autre .BAT). Aucune modification de répertoire ou
de contenu de répertoire ailleurs que dans celui où vous dézippez
- ne contient aucun programme qui s'exécuterait à la décompression (.EXE, .BAT, .SCR ou autre .VXD) ou qui seraient lancés plus tard (reboot)
- passez-le à l'antivirus avant décompression si vous êtes inquiets.
- le programme ne change pas la base de registre et ne modifie aucun autre répertoire de votre machine
- pour supprimer le projet, effacez simplement le répertoire.
Voici le .ZIP:
Comme d'habitude: - nous vous remercions de nous signaler toute erreur, inexactitude ou
problème de téléchargement en envoyant un e-mail à jcolibri@jcolibri.com. Les corrections qui en résulteront pourront aider les prochains lecteurs
- tous vos commentaires, remarques, questions, critiques, suggestion d'article, ou mentions d'autres sources sur le même sujet seront de même les bienvenus à jcolibri@jcolibri.com.
- plus simplement, vous pouvez taper (anonymement ou en fournissant votre e-mail pour une réponse) vos commentaires ci-dessus et nous les envoyer en cliquant "envoyer" :
- et si vous avez apprécié cet article, faites connaître notre site, ajoutez un lien dans vos listes de liens ou citez-nous dans vos
blogs ou réponses sur les messageries. C'est très simple: plus nous aurons de visiteurs et de références Google, plus nous écrirons d'articles.
7 - L'auteur
John COLIBRI est passionné par le développement Delphi et les applications de Bases de Données. Il a écrit de nombreux livres et articles, et partage son temps entre le développement de projets (nouveaux projets, maintenance, audit, migration BDE, migration Xe_n, refactoring) pour ses clients, le
conseil (composants, architecture, test) et la
formation. Son site contient des articles
avec code source, ainsi que le programme et le calendrier des stages de formation Delphi, base de données, programmation objet, Services Web, Tcp/Ip et
UML qu'il anime personellement tous les mois, à Paris, en province ou sur site client.
|