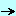|
Coli_DIFF: Différence entre 2 fichiers - John COLIBRI. |
- résumé : utilitaire qui calcule et affiche les différence entre deux textes ASCII
- mots clé : DIFF, DIFFing, différence textuelle
- logiciel utilisé : Windows XP personnel, Delphi 6.0
- matériel utilisé : Pentium 2.800 Mhz, 512 Meg de mémoire, 250 Giga disque dur
- champ d'application : Delphi 1 à 2006 sur Windows
- niveau : développeur Delphi
- plan :
1 - Calcul de Différence Textuelle Pour certains clients, nous fournissons les sources des projets que nous développons pour eux. Le client est alors libre de faire évoluer le logiciel à
sa guise. Si par la suite, il souhaite nous faire intervenir à nouveau, il nous faut au préalable comprendre ce qui a été modifié au projet tel que nous l'avions livré. Il existe plusieurs outils de différence textuelle, WINDIFF étant peut être le
plus connu. Nous souhaitions néanmoins disposer d'un outil qui aille au delà des possibilités de WINDIFF. C'est pourquoi nous avons élaboré un utilitaire spécifique. Nous allons présenter ici la version de base.
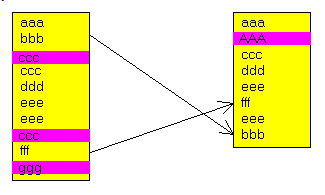
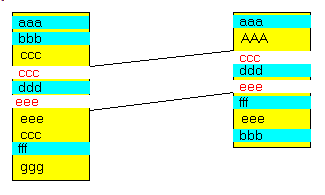
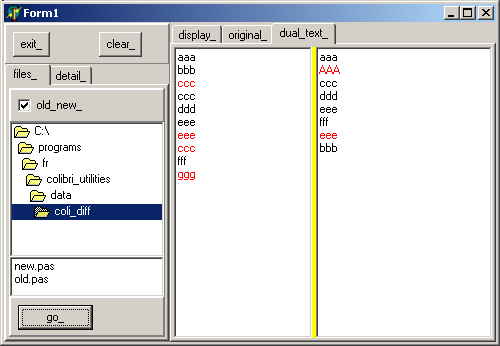
2 - L'algorithme de Calcul de DIFFérence Voici tout d'abord un exemple de textes: - considérons le texte de départ suivant:
- après ajout, effacement, déplacement, le texte devient, par exemple:
- une comparaison des deux textes met en évidence
- les lignes en violet qui figurent dans le texte original, ou sa nouvelle
version uniquement
- les déplacements de lignes:
Pour obtenir le résultat précédent, nous avons utilisé l'algorithme suivant:
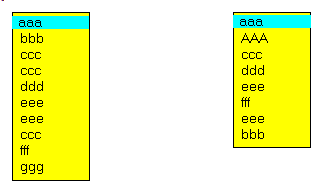
- dans nos deux textes, il ya certaines lignes qui sont présentes en un seul exemplaire dans les deux textes. Nous sommes certains que ces lignes là font partie sans ancune ambiguité, ni risque d'erreur, des lignes communes aux deux textes.
C'est le cas, par exemple pour la ligne "aaa": mais également pour les lignes "bbb", "ddd" et "fff":
- en partant des lignes présentes une seule fois dans les deux textes, nous pouvons, pour chacune de ces lignes
- rechercher les lignes identiques avant la ligne
- rechercher les lignes identiques après la ligne
Prenons, par exemple la ligne "ddd": - avant "ddd", les deux textes contiennent tous les deux "ccc". Nous ajoutons donc cette ligne au "bloc commun"
- après "ddd", les deux texte contiennent tous les deux "eee", que nous
ajoutons au "bloc commun"
Dans notre cas, avant "ccc" et après "eee", les deux textes divergent. Voici donc le bloc calculé à partir de "ddd":
Ces calculs sont effectués pour chaque ligne présente une seule fois dans les deux textes - après cette passe, il reste les lignes ne faisant partie d'aucun bloc, soit dans le texte original, soit dans sa nouvelle version.
Il nous faut donc - créer une structure contenant les lignes distinctes de chaque texte.
- pour chaque ligne différente, calculer sa fréquence dans le texte de départ et dans le nouveau texte
- pour les lignes présentes une seule fois dans chaque texte, calculer les lignes identiques avant et après cette ligne unique commune
Ensuite, il faut trouver un moyen de visualiser le résultat
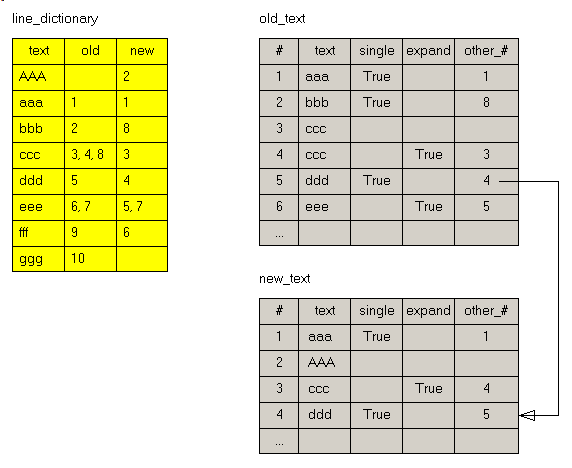
3 - Le Projet Delphi 3.1 - Les Structures Pour construire notre dictionnaire des lignes des deux textes, nous utilisons une arbre binaire, dont chaque ligne comporte
- la ligne (plus exactement la ligne sans les espaces de départ et de fin)
- la fréquences de cette ligne dans les deux textes
- la liste des numéros de ligne où cette ligne apparaît dans chacun des textes
(actuellement, seul le numéro de la première occurence serait nécessaire pour notre algorithme)
Les lignes de chaque texte sont gérées par une liste linéaire, contenant, pour chaque ligne - le numéro de la ligne dans le texte
- une référence vers l'entrée de la ligne dans le dictionnaire
- des booléens qui stockent le fait que la ligne a été reconnue comme une ligne unique, ou comme une extension "avant" ou "arrière" d'une ligne unique
- le numéro de cette ligne dans l'autre texte, si elle est présente dans l'autre texte
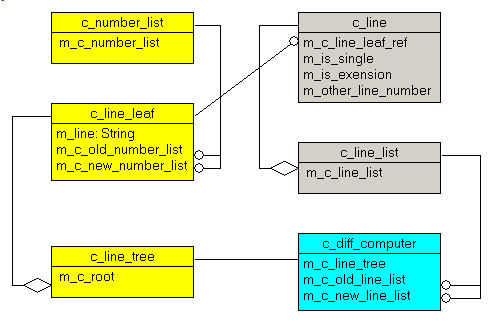
Au niveau UML, nous avons:
Schématiquement, pour l'exemple précédent:
3.2 - Le dictionnaire Ces structures gèrent le dictionnaire des lignes. Elles contiennent la liste de
toutes les exemplaires de lignes figurant dans les deux textes, avec les informations sur la fréquence et la position de ces lignes dans chaque texte.
Les séquences de numéros de lignes sont gérés par:
c_line_number_list= Class(c_basic_object)
m_c_line_number_list: tList;
constructor create_line_number_list;
procedure add_line_number(p_line_number: Integer);
function f_line_number(p_index: Integer): Integer;
function f_display_line_number_list: String;
function f_index_of_line_number(p_line_number: Integer): Integer;
Destructor Destroy; Override;
end; // c_line_number_list
|
Chaque ligne unique est stockée dans la classe: c_diff_line_leaf=
class(c_basic_object)
m_c_left, m_c_right: c_diff_line_leaf;
m_the_line: String;
// -- occurence count in old and new
m_old_line_count, m_new_line_count: Integer;
// -- the linr numbers where this line occurs
m_c_old_line_number_list, m_c_new_line_number_list: c_line_number_list;
constructor create_diff_line_leaf(p_string: String;
p_in_old_file: Boolean; p_line_number: Integer);
function f_display_diff_line_leaf: String;
procedure display_leaf; Virtual;
procedure display_leaf_line_number_list;
function f_index_in_old_lines_list(p_old_index: Integer): Integer;
function f_line_number_in_new_lines_list(
p_index_in_old_lines_list: Integer): Integer;
Destructor Destroy; Override;
end; // c_diff_line_leaf
|
Le dictionnaire qui contient ces lignes est défini par:
c_diff_line_tree=
class(c_basic_object)
m_c_root: c_diff_line_leaf;
// -- stats
m_uniques_in_old, m_uniques_in_new: Integer;
constructor create_diff_line_tree(p_name: String);
function f_c_add_diff_line_leaf(p_the_line: String;
p_in_old_file: boolean; p_line_number: Integer): c_diff_line_leaf;
procedure display_tree(p_with_line_number_list: Boolean);
Destructor Destroy; Override;
end; // c_diff_line_tree
| La procédure qui ajoute une nouvelle ligne est la suivante:
function c_diff_line_tree.f_c_add_diff_line_leaf(p_the_line: String;
p_in_old_file: boolean; p_line_number: Integer): c_diff_line_leaf;
function f_c_add_diff_line_leaf_recursive(
var pv_c_leaf: c_diff_line_leaf): c_diff_line_leaf;
begin
if pv_c_leaf= nil
then begin
pv_c_leaf:= c_diff_line_leaf.create_diff_line_leaf(p_the_line,
p_in_old_file, p_line_number);
// -- return the new leaf as the result
Result:= pv_c_leaf;
end
else
if p_the_line< pv_c_leaf.m_the_line
then Result:= f_c_add_diff_line_leaf_recursive(pv_c_leaf.m_c_left)
else
if p_the_line> pv_c_leaf.m_the_line
then Result:= f_c_add_diff_line_leaf_recursive(pv_c_leaf.m_c_right)
else begin
// -- equal: return this c_diff_line_leaf
Result:= pv_c_leaf;
// -- update the counts and line numbers
with pv_c_leaf do
begin
if p_in_old_file
then begin
Inc(m_old_line_count);
m_c_old_line_number_list.add_line_number(p_line_number);
end
else begin
Inc(m_new_line_count);
m_c_new_line_number_list.add_line_number(p_line_number);
end;
end; // with pv_c_leaf
end;
end; // f_c_add_diff_line_leaf_recursive
begin // f_c_add_diff_line_leaf
// -- find or create the c_diff_line_leaf in the tree
Result:= f_c_add_diff_line_leaf_recursive(m_c_root);
end; // f_c_add_diff_line_leaf
|
3.3 - Les listes de lignes
Pour chaque texte, nous construisons une liste de lignes. La ligne est définie par:
c_diff_line= Class(c_basic_object)
m_c_diff_line_leaf_ref: c_diff_line_leaf;
m_line_index: Integer;
// -- the corresponding line in the other text
m_line_number_in_other: Integer;
m_is_single: Boolean;
m_is_expanded: Boolean;
Constructor create_diff_line(p_name: String;
p_line_index: Integer;
p_c_diff_line_leaf_ref: c_diff_line_leaf);
function f_display_diff_line: String;
function f_c_self: c_diff_line;
procedure update_diff_line(p_is_single, p_is_expanded: Boolean;
p_line_number_in_new: Integer);
Destructor Destroy; Override;
end; // c_diff_line
|
Et la liste est définie par:
c_diff_line_list=
Class(c_basic_object)
m_c_diff_line_list: tStringList;
Constructor create_diff_line_list(p_name: String);
function f_diff_line_count: Integer;
function f_c_diff_line(p_diff_line_index: Integer): c_diff_line;
function f_index_of(p_diff_line_name: String): Integer;
function f_c_find_by_diff_line(p_diff_line_name: String): c_diff_line;
procedure add_diff_line(p_diff_line_name: String; p_c_diff_line: c_diff_line);
function f_c_add_diff_line(p_diff_line_name: String;
p_c_diff_line_leaf_ref: c_diff_line_leaf): c_diff_line;
procedure display_diff_line_list;
Destructor Destroy; Override;
end; // c_diff_line_list
|
3.4 - Le calcul des blocs communs La classe de calcul est:
c_compute_diff=
class(c_text_file)
m_c_new_text_file: c_text_file;
m_c_diff_line_tree: c_diff_line_tree;
m_c_old_diff_line_list, m_c_new_diff_line_list: c_diff_line_list;
m_display_seeds: Boolean;
m_max_old, m_max_new: Integer;
constructor create_compute_diff(p_name, p_file_name, p_new_file_name: String);
procedure load_lines;
function f_load_lines: Boolean;
procedure find_singles(p_old_start, p_old_end: Integer);
procedure find_all_singles;
procedure extend_singles(p_old_start, p_old_end: Integer);
procedure extend_all_singles;
destructor Destroy; Override;
end; // c_compute_diff
| Et: - nous chargeons les fichiers par:
procedure c_compute_diff.load_lines;
begin
m_c_diff_line_tree:= c_diff_line_tree.create_diff_line_tree('tree');
m_c_old_diff_line_list:= c_diff_line_list.create_diff_line_list('old');
m_c_new_diff_line_list:= c_diff_line_list.create_diff_line_list('new');
while m_buffer_index< m_buffer_size do
begin
f_read_line;
with m_c_line do
begin
m_c_old_diff_line_list.f_c_add_diff_line('odl',
m_c_diff_line_tree.f_c_add_diff_line_leaf(Trim(m_the_line),
k_in_old_file_true, m_c_old_diff_line_list.m_c_diff_line_list.Count));
end; // with m_c_line
end; // while
with m_c_new_text_file do
begin
while m_buffer_index< m_buffer_size do
begin
f_read_line;
with m_c_line do
begin
if m_line_number> m_max_new
then break;
m_c_new_diff_line_list.f_c_add_diff_line('new',
m_c_diff_line_tree.f_c_add_diff_line_leaf(Trim(m_the_line),
k_in_old_file_false, m_c_new_diff_line_list.m_c_diff_line_list.Count));
end; // with m_c_line
end; // while
end; // with m_c_new_text_file
end; // load_lines
|
- les lignes en un exemplaire dans chaque texte sont calculées par:
procedure c_compute_diff.find_singles(p_old_start, p_old_end: Integer);
var l_old_index: Integer;
l_index_in_old_lines_list, l_line_number_in_new_lines_list: Integer;
begin
with m_c_old_diff_line_list do
for l_old_index:= p_old_start to p_old_end do
if (f_c_diff_line(l_old_index).m_c_diff_line_leaf_ref.m_old_line_count= 1)
and(f_c_diff_line(l_old_index).m_c_diff_line_leaf_ref.m_new_line_count= 1)
then begin
with f_c_diff_line(l_old_index), m_c_diff_line_leaf_ref do
begin
m_is_single:= True;
l_index_in_old_lines_list:= l_old_index;
// -- there is only on line in new_line_list
l_line_number_in_new_lines_list:= m_c_new_line_number_list.f_line_number(0);
// -- update the "line_index_in_other" link
m_line_number_in_other:= l_line_number_in_new_lines_list;
// -- adjust the ref counts in the c_line_leaf
Dec(m_old_line_count);
Dec(m_new_line_count);
end; // with f_c_diff_line(l_old_index)
// -- for display purposes, also update new
m_c_new_diff_line_list.f_c_diff_line(l_line_number_in_new_lines_list)
.update_diff_line(k_is_single_true, k_is_expanded_false, l_old_index);
end; // // for l_index
end; // find_singles
| - et les extensions avant / arrière sont ajoutées ainsi:
procedure c_compute_diff.extend_singles(p_old_start, p_old_end: Integer);
procedure extend_single(var pv_old_index: Integer);
var l_old_before_index, l_new_before_index: Integer;
l_old_after_index, l_new_after_index: Integer;
begin
with m_c_old_diff_line_list do
begin
// -- try to extend before
l_old_before_index:= pv_old_index- 1;
l_new_before_index:= f_c_diff_line(pv_old_index).m_line_number_in_other- 1;
while (l_old_before_index>= 0)
and (l_new_before_index>= 0)
and (f_c_diff_line(l_old_before_index).m_line_number_in_other< 0)
and (f_c_diff_line(l_old_before_index).m_c_diff_line_leaf_ref.m_the_line
= m_c_new_diff_line_list.f_c_diff_line(l_new_before_index).m_c_diff_line_leaf_ref.m_the_line) do
begin
// -- adjust the ref counts in the c_line_leaf
with f_c_diff_line(l_old_before_index), m_c_diff_line_leaf_ref do
begin
Dec(m_old_line_count);
Dec(m_new_line_count);
m_is_expanded:= True;
end; // with f_c_diff_line , m_c_diff_line_leaf_ref
// -- for display purposes, also update new
m_c_new_diff_line_list.f_c_diff_line(l_new_before_index)
.update_diff_line(k_is_single_false, k_is_expanded_true, l_old_before_index);
// -- try the lines above
Dec(l_old_before_index); Dec(l_new_before_index);
end; // while (l_index_before
// -- try to extend after
l_old_after_index:= pv_old_index+ 1;
l_new_after_index:= f_c_diff_line(pv_old_index).m_line_number_in_other+ 1;
while (l_old_after_index< m_c_diff_line_list.Count)
and (f_c_diff_line(l_old_after_index).m_line_number_in_other< 0)
and (f_c_diff_line(l_old_after_index).m_c_diff_line_leaf_ref.m_the_line
= m_c_new_diff_line_list.f_c_diff_line(l_new_after_index).m_c_diff_line_leaf_ref.m_the_line) do
begin
// -- adjust the ref counts in the c_line_leaf
with f_c_diff_line(l_old_after_index), m_c_diff_line_leaf_ref do
begin
Dec(m_old_line_count);
Dec(m_new_line_count);
m_is_expanded:= True;
end; // with f_c_diff_line , m_c_diff_line_leaf_ref
// -- for display purposes, also update new
m_c_new_diff_line_list.f_c_diff_line(l_new_after_index)
.update_diff_line(k_is_single_false, k_is_expanded_true, l_old_after_index);
// -- try the next lines
Inc(l_old_after_index); Inc(l_new_after_index);
end; // while (l_index_before
// -- continue after the last "after"
pv_old_index:= l_old_after_index;
end; // m_c_old_diff_line_list
end; // extend_single
var l_old_index: Integer;
begin // extend_singles
with m_c_old_diff_line_list do
begin
l_old_index:= p_old_start;
while l_old_index<= p_old_end do
if f_c_diff_line(l_old_index).m_is_single
then extend_single(l_old_index)
else Inc(l_old_index);
end; // with m_c_old_diff_line_list
end; // extend_singles
|
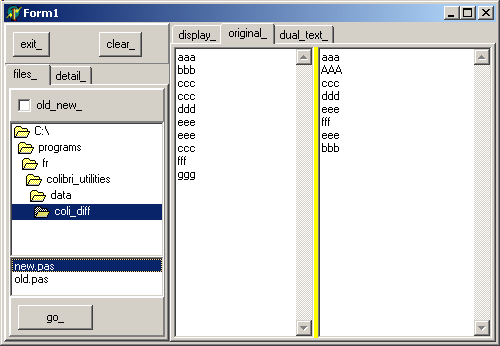
3.5 - La sélection du texte Nous utilisons un DirectoryListBox et un FileListbox, avec une tCheckBox pour sélectionner le fichier original ou sa nouvelle version
3.6 - L'affichage Deux tRichEdits séparés par un splitter permettent d'afficher les deux textes
3.7 - Mini manuel Pour utiliser le programme
4 - Télécharger le code source Delphi Vous pouvez télécharger:
- coli_diff.zip : le projet et toutes ses unités, permettant le calcul de différence textuelle (38 K)
Ce .ZIP qui comprend: - le .DPR, la forme principale, les formes annexes eventuelles
- les fichiers de paramètres (le schéma et le batch de création)
- dans chaque .ZIP, toutes les librairies nécessaires à chaque projet (chaque .ZIP est autonaume)
Ces .ZIP, pour les projets en Delphi 6, contiennent des chemins RELATIFS. Par conséquent: - créez un répertoire n'importe où sur votre machine
- placez le .ZIP dans ce répertoire
- dézippez et les sous-répertoires nécessaires seront créés
- compilez et exécutez
Ces .ZIP ne modifient pas votre PC (pas de changement de la Base de Registre, de DLL ou autre). Pour supprimer le projet, effacez le répertoire.
La notation utilisée est la notation alsacienne qui consiste à préfixer les identificateurs par la zone de compilation: K_onstant, T_ype, G_lobal,
L_ocal, P_arametre, F_unction, C_lasse. Elle est présentée plus en détail dans l'article La
Notation Alsacienne
Comme d'habitude: - nous vous remercions de nous signaler toute erreur, inexactitude ou
problème de téléchargement en envoyant un e-mail à jcolibri@jcolibri.com. Les corrections qui en résulteront pourront aider les prochains lecteurs
- tous vos commentaires, remarques, questions, critiques, suggestion d'article, ou mentions d'autres sources sur le même sujet seront de même les bienvenus à jcolibri@jcolibri.com.
- plus simplement, vous pouvez taper (anonymement ou en fournissant votre e-mail pour une réponse) vos commentaires ci-dessus et nous les envoyer en cliquant "envoyer" :
- et si vous avez apprécié cet article, faites connaître notre site, ajoutez un lien dans vos listes de liens ou citez-nous dans vos
blogs ou réponses sur les messageries. C'est très simple: plus nous aurons de visiteurs et de références Google, plus nous écrirons d'articles.
5 - L'auteur
John COLIBRI est passionné par le développement Delphi et les applications de Bases de Données. Il a écrit de nombreux livres et articles, et partage son temps entre le développement de projets (nouveaux projets, maintenance, audit, migration BDE, migration Xe_n, refactoring) pour ses clients, le
conseil (composants, architecture, test) et la
formation. Son site contient des articles
avec code source, ainsi que le programme et le calendrier des stages de formation Delphi, base de données, programmation objet, Services Web, Tcp/Ip et
UML qu'il anime personellement tous les mois, à Paris, en province ou sur site client.
|