|
Iso CD Extractor - John COLIBRI. |
- mots clé:extraction de fichiers d'une image ISO - CD - YellowBook
- logiciel utilisé: Windows XP, Delphi 6.0
- matériel utilisé: Pentium 1.400Mhz, 256 M de mémoire
- champ d'application: Delphi 1 à 6 sur Windows, Kylix
- niveau: programmeur Delphi
- plan:
1 - Introduction De nombreux logiciels sont proposés sur le Web sous forme de fichier "ISO". Il s'agit d'un paquet de données ayant un format particulier. Ce format est adapté
aux lecteurs de CD ROM, et nous ne pouvons donc pas afficher le contenu de ces fichiers dans l'Explorateur Windows. Il faut alors - soit placer ces fichiers sur un disque vierge
- soit extraire le contenu du fichier .ISO et les copier dans un répertoire classique
N'étant pas arrivé à copier un fichier .ISO téléchargé, j'ai cherché un programme pour analyser ce fichier et suis tombé sur
http://isolib.xenome.info/. Ce site propose un projet permettant l'analyse, l'extraction de fichiers, et à terme, l'écriture de CD. Le programme est aussi sur SourceForge. Notre projet est un descendant direct de ce projet (tIsoLib).
Nous allons ici: - présenter le format des fichiers .ISO
- afficher la liste des répertoires et des fichiers
- extraire les fichiers dans un répertoire Windows.
2 - Format ISO
Format général Les données placées sur un CD ROM peuvent être organisées selon plusieurs formats: des formats pour la musique, pour les films, pour les données informatiques etc.
Ce qui nous intéresse ici, c'est le format des données informatiques. Plusieurs tentatives de normalisation ont été entreprises, et plusieurs formats, tels ISO 9660, High Sierra, Joliet etc ont été publiés.
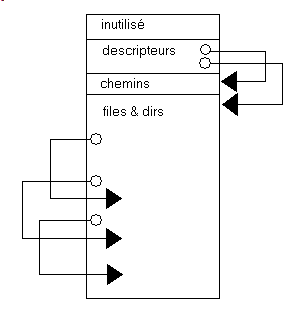
Nous analyserons le format ISO 9660, qui serait similaire à High Sierra. Un CD ROM ISO est organisé de la façon suivante: - les données sont groupées par paquets de 2048 ou 2336 octets
- la structure est la suivante
- les 16 premiers secteurs sont inutilisés
- à partir du secteur 16 sont situés des descripteurs de volume
- vient une table des chemins
- puis nous trouvons le répertoire principal
- ce répertoire principal indique où se trouvent
- les fichiers contenus dans le répertoire principal
- les sous-répertoire qui contiennent d'autres fichiers
Globalement nous avons donc:
Et: - les descripteurs vont être détaillés ci-dessous. Ils permettent essentiellement de savoir où se trouve le "master dir"
- la table des chemins ne sera pas utilisée ici
- le "master dir" est le répertoire global. Il a la même structure que les sous-répertoires: il contient des entrées pour des sous-répertoires ou des fichiers:
- chaque sous-répertoire contient donc aussi des entrées de
sous-répertoires ou de fichiers
- les entrées de fichiers permettent de localiser les fichiers
Les Descripteurs Chaque CD contient 2 descripteurs ou plus: - il y a deux descripteurs principaux:
- le descripteur primaire est le plus important. C'est lui qui nous donne accès à la table des matière principale
- le descripteur final sert à indiquer la fin des descripteurs
- entre les deux, 0 ou plusieurs descripteurs optionnels
- le descripteur de partition
- le descripteur de boot
Suivant l'operating system destinataire (Linux, Mac etc) il y aura plusieurs de ces descripteurs.
Comme il ne nous servent pas à récupérer nos données, nous ne nous en occuperons pas ici
La détection du type de CD se fait en vérifiant que les octets situés à 16* 2048 + 1 sont bien "CDOO1". Il s'agit alors bien du format "YellowBook, mode
1". Les secteurs de descripteurs contiennent en position 0 un octet qui définit le type de descripteur. Il suffit donc de lire le secteur jusqu'à ce que nous tombions sur le secteur de "fin de descripteurs".
Le descripteur primaire qui a la signature $01 est défini par le type Delphi suivant:
t_primary_descriptor= packed record
StandardIdentifier: array[0..4] of Char;
VolumeDescriptorVersion: Byte;
unused: Byte;
SystemIdentifier: array[0..31] of Char;
VolumeIdentifier: array[0..31] of Char;
Unused2: array[0..7] of Byte;
VolumeSpaceSize: TBothEndianDWord;
Unused3: array[0..31] of Byte;
VolumeSetSize: TBothEndianWord;
VolumeSequenceNumber: TBothEndianWord;
LogicalBlockSize: TBothEndianWord;
PathTableSize: TBothEndianDWord;
LocationOfTypeLPathTable: LongWord;
LocationOfOptionalTypeLPathTable: LongWord;
LocationOfTypeMPathTable: LongWord;
LocationOfOptionalTypeMPathTable: LongWord;
RootDirectory: TRootDirectoryRecord; // <===
VolumeSetIdentifier: array[0..127] of Char;
PublisherIdentifier: array[0..127] of Char;
DataPreparerIdentifier: array[0..127] of Char;
ApplicationIdentifier: array[0..127] of Char;
CopyrightFileIdentifier: array[0..36] of Char;
AbstractFileIdentifier: array[0..36] of Char;
BibliographicFileIdentifier: array[0..36] of Char;
VolumeCreationDateAndTime: TVolumeDateTime;
VolumeModificationDateAndTime: TVolumeDateTime;
VolumeExpirationDateAndTime: TVolumeDateTime;
VolumeEffectiveDateAndTime: TVolumeDateTime;
FileStructureVersion: Byte;
ReservedForFutureStandardization: Byte;
// -- the remaining bytes
ApplicationUse: array[0..511] of Byte;
ReservedForFutureStandardization2: array[0..652] of Byte;
end; // t_primary_descriptor
|
Et: - StandardIdentifier est la signature "CD001" citée plus haut
- RootDirectory est un sous enregistrement qui indique où se trouve le répertoire principal:
TRootDirectoryRecord= packed record
LengthOfDirectoryRecord: Byte;
ExtendedAttributeRecordLength: Byte;
LocationOfExtent: TBothEndianDWord;
DataLength: TBothEndianDWord;
RecordingDateAndTime: TDirectoryDateTime;
FileFlags: Byte;
FileUnitSize: Byte;
InterleaveGapSize: Byte;
VolumeSequenceNumber: TBothEndianWord;
LengthOfFileIdentifier: Byte; // = 1
FileIdentifier: Byte; // = 0
end; // TRootDirectoryRecord
|
et: - LocationOfExtent est le numéro de secteur du répertoire principal
- DataLength nous donne le nombre d'octets de ce répertoire. En divisant
par 2048 nous obtenons le nombre de secteurs qu'il utilise.
Le Format d'une entrée Les répertoires sont composés d'entrées. Chaque entrée a le format suivant:
t_directory_entry= packed record
LengthOfDirectoryRecord: Byte;
ExtendedAttributeRecordLength: Byte;
LocationOfExtent: TBothEndianDWord;
DataLength: TBothEndianDWord;
RecordingDateAndTime: TDirectoryDateTime;
FileFlags: Byte;
FileUnitSize: Byte;
InterleaveGapSize: Byte;
VolumeSequenceNumber: TBothEndianWord;
LengthOfFileIdentifier: Byte;
// -- followed by FileIdentifier and padding bytes
end; // t_directory_entry
|
Plusieurs facteurs compliquent l'analyse des entrées: - chaque entrée a une partie fixe (tailles, indicateurs divers) et un nom de taille variable situé après la partie fixe
- une entrée ne peut pas chevaucher deux secteurs
- une entrée peut contenir un nom de taille 0, mais tout de même être suivie par d'autres entrées valides
Les champs qui nous intéressent sont alors: - LengthOfFileIdentifier: le nombre d'octets utilisés par le nom
- FileFlags: détermine le type d'entrée. Essentiellement le bit 1 qui est à 0 pour un fichier, à 1 pour un sous-répertoire
- LocationOfExtent: le numéro de secteur des données (le sous-répertoire ou le fichier)
- DataLength: le nombre d'octets utiles
3 - Le Programme Organisation Nous avons utilisé les fichiers suivants:
- u_iso_definitions qui contient les définitions des descripteurs et des entrées
- u_c_iso_file_read qui:
- détecte le type de fichier .ISO (en lisant les octets de signature)
- contient un tFileStream permettant de lire le fichier .ISO secteur par secteur
- un structure arborescente récursive pour stocker:
- pour les répertoires:
- leur nom
- la liste de leurs sous-répertoires
- la liste de leurs fichiers
- pour les fichiers:
- leur nom
- leur numéro de secteur et leur taille
Nous avons ici utilisé notre classique encapsulation de tStringList (cf u_c_tstringlist). La définition est la suivante:
c_iso_file= // one file
Class(c_basic_object)
// -- m_name: the file+ extension name
m_iso_sector_number: Integer;
m_iso_size: Integer;
Constructor create_iso_file(p_name: String;
p_iso_sector_number, p_iso_size: Integer);
function f_display_file: String;
function f_c_self: c_iso_file;
Destructor Destroy; Override;
end; // c_iso_file
c_iso_path= // -- recursive structure containing the iso directories
Class(c_basic_object)
// -- m_name: the full path
m_segment: String;
m_c_parent_path: c_iso_path;
m_c_file_list: tStringList;
m_c_sub_path_list: tStringList;
Constructor create_iso_path(p_name, p_segment: String;
p_c_parent_path: c_iso_path);
function f_c_self: c_iso_path;
function f_file_count: Integer;
function f_c_file(p_file_index: Integer): c_iso_file;
function f_index_of_file(p_file_name: String): Integer;
function f_c_find_by_file(p_file_name: String): c_iso_file;
procedure add_file(p_file_name: String; p_c_file: c_iso_file);
function f_c_add_file(p_file_name: String;
p_iso_sector_number, p_iso_size: Integer): c_iso_file;
procedure display_file_list;
function f_sub_path_count: Integer;
function f_c_sub_path(p_sub_path_index: Integer): c_iso_path;
function f_c_find_sub_path_by_name(p_sub_path_name: String): c_iso_path;
procedure add_sub_path(p_sub_path_name: String; p_c_sub_path: c_iso_path);
function f_c_add_sub_path(p_sub_path_name, p_segment: String): c_iso_path;
function f_c_get_or_add_sub_path(p_sub_path_name, p_segment: String): c_iso_path;
procedure display_sub_path_list;
procedure display_path_and_file;
Destructor Destroy; Override;
end; // c_iso_path
|
- l'arborescence est construite par une classe c_analyze_iso_file qui lit le fichier et place les cellules en fonction du contenu du fichier
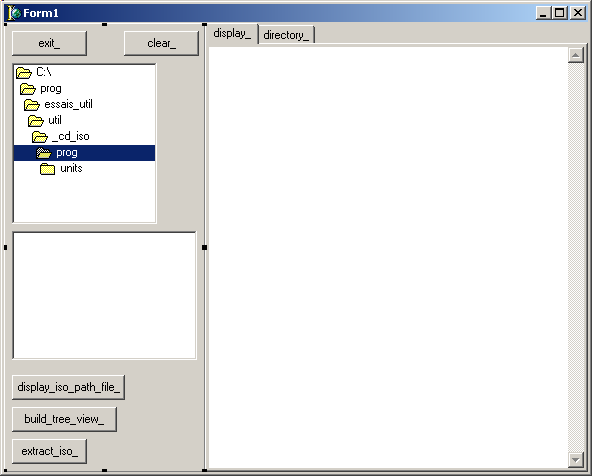
Le programme principal:
- contient une tDirectoryListBox associé à une tFileListBox qui permettent la sélection du fichier .ISO et le lancement de la construction de l'arbre
- le bouton display_path_file visualise l'arborescence de façon indentée
(avec la position des fichiers et leur taille)
- le bouton build_tree_view_ permet de visualiser la structure dans un tTreeView
- le bouton extract_iso_ copie tous les fichier du fichier .ISO dans un
répertoire de votre choix
4 - Utilisation Pour utiliser le programme:
 | récupérez sur le Web le fichier .ISO qui vous intéresse
| | | téléchargez le .ZIP
|
| | décompactez-le dans n'importe quel répertoire
| | | exécutez-le
|
| | sélectionnez à l'aide de la tDirectoryListBox le chemin
| | |
cliquez dans la tFileListBox le fichier que vous souhaitez analyser / décompacter
|  | le programme construit l'arborescence en mémoire
|
| | pour visualiser le contenu du .ISO
- cliquez sur display_path_file pour lister les répertoires et fichiers
- cliquez sur build_tree_view_ pour construire le tTreeView qui sera visible dans l'onglet directory_
| | |
pour extraire les fichiers et les placer dans une arborescence Windows
- créez le répertoire avec l'Explorateur Windows
- changez le nom k_save_path dans le fichiers (sinon le répertoire
"c:\prog\essais_util\util\_cd_iso\_data\" sera créé et utilisé)
- cliquez extract_iso_. Attendez quelques secondes que les fichiers soient copiés
|
5 - Améliorations
Améliorations Ce programme a été crée pour nous permettre de décompacter un .ISO que nous avions téléchargé. Il n'a pas été testé sur d'autres fichiers. Le programme pourrait être amélioré:
- en lisant directement depuis le lecteur, ou en gravant des fichiers sur le CD
- en testant et en ajoutant le traitement des autres formats (JOLIET etc)
Je recherche
D'après certains messages sur le Web, XP contiendrait des API, "mal documentées" (c'est peu dire), permettant d'écrire des CD en utilisant les DLL (NERO ou autre). Si quelqu'un a des informations, et quelques lignes de
programmes, elles sont les bienvenues. Graver mes CD de sauvegarde est toujours une galère. Il faut en effet: - extraire les fichiers manuellement
- vérifier approximativement que la taille ne dépasse pas la capacité du CD
- lancer une mystérieux .EXE qui grave, ou qui envoie des messages sibyllins s'il n'y arrive pas
Or tout le travail de préparation peut être avantageusement effectué en Delphi,
en utilisant des procédure inverses de celles présentées ici pour la lecture. Si on connaît les primitives d'écriture, la gravure des secteurs préparés devrait alors être un jeu d'enfant. Si on connaît les primitives d'écriture...
6 - Télécharger le source Nous avons placé le projet dans un .ZIP qui comprend: - le .DPR, la forme principale
- les unités citées ici
- nos utilitaires habituels d'affichage, de log etc
Ce .ZIP est auto suffisant. Il contient des chemins RELATIFS. Par conséquent: - créez un répertoire n'importe où sur votre machine
- placez le .ZIP dans ce répertoire
- dézippez et les sous-répertoires nécessaires seront créés
- compilez et exécutez
Au niveau sécurité: - les .ZIP:
- ne modifient pas votre PC (pas de changement de la Base de Registre, d'écrasement de DLL ou autre .BAT). Aucune modification de répertoire ou
de contenu de répertoire ailleurs que dans celui où vous dézippez
- ne contiennent aucun programme qui s'exécuterait à la décompression (.EXE, .BAT, .SCR ou autre .VXD) ou qui seraient lancés plus tard (reboot)
- passez-les à l'antivirus avant décompression si vous êtes inquiets.
- les programmes ne changent pas la base de registre et ne modifient aucun autre répertoire de votre machine
- pour supprimer le projet, effacez simplement le répertoire.
Voici le .ZIP:
Comme d'habitude: - nous vous remercions de nous signaler toute erreur, inexactitude ou problème de téléchargement en envoyant un e-mail à jcolibri@jcolibri.com. Les corrections
qui en résulteront pourront aider les prochains lecteurs
- tous vos commentaires, remarques, questions, critiques, suggestion d'article, ou mentions d'autres sources sur le même sujet seront de même
les bienvenus à jcolibri@jcolibri.com.
- plus simplement, vous pouvez taper (anonymement ou en fournissant votre e-mail pour une réponse) vos commentaires ci-dessus et nous les envoyer en
cliquant "envoyer" :
- et si vous avez apprécié cet article, faites connaître notre site,
ajoutez un lien dans vos listes de liens ou citez-nous dans vos blogs ou réponses sur les messageries. C'est très simple: plus nous aurons de visiteurs et de références Google, plus nous écrirons d'articles.
7 - Conclusion Ce projet permet d'analyser le contenu d'un fichier .ISO et d'en extraire les fichiers dans un répertoire Windows
8 - Références - http://isolib.xenome.info/ (ou SourceForge)
Le projet Delphi dont nous sommes paris
9 - L'auteur John COLIBRI est passionné par le développement Delphi et les applications de Bases de Données. Il a écrit de nombreux livres
et articles, et partage son temps entre le développement de projets (nouveaux projets, maintenance, audit, migration BDE, migration Xe_n,
refactoring) pour ses clients, le conseil (composants, architecture, test) et la
formation. Son site contient des articles
avec code source, ainsi que le programme et le calendrier des stages de formation Delphi, base de données, programmation objet, Services Web, Tcp/Ip et
UML qu'il anime personellement tous les mois, à Paris, en province ou sur site client.
|