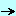|
Interprète d'Expression - John COLIBRI. |
- mots clé:interprète - compilateur - analyse syntaxique et lexicale - grammaire - BNF, EBNF
- logiciel utilisé: Windows XP, Delphi 6.0
- matériel utilisé: Pentium 1.400Mhz, 256 M de mémoire
- champ d'application: Delphi 1 à 6 sur Windows, Kylix
- niveau: débutant en Pascal et Delphi
- uses:
- plan:
1 - Introduction Cet article présente un petit interprète d'expressions arithmétiques. Le but
est de pouvoir calculer le résultat d'une expression arithmétique founie dans une STRING. Nous présentons plusieurs versions de l'interprète: - un calcul direct
- un construction d'un arbre symbolique suivi de son interprétation
Ce programme n'a aucune prétention d'universalité. Je m'étais simplement engagé auprès d'un stagiaire à fournir le code d'un interprète simple, et donc voici le programme C'est bien connu, tous les formateurs Delphi fournissent des
exemples avec explicatif, figure et code source après les stages qu'ils ont animés...
2 - Un premier interprète simple 2.1 - Principe Nous avions jadis présenté dans Pascalissime le principe d'un
mini-compilateur. Cet article comportait: - description de la notation EBNF
- l'explication parallélisme entre EBNF et les procédure d'un analyseur
- le principe d'une machine à pile
- un programme effectuant l'analyse et l'exécution d'un petit programme
Le lecteur pourra se reporter à ces articles. Ici nous partirons de la grammaire des expressions, puis nous générerons
l'analyseur syntaxique et créerons l'interprète manuellement.
2.2 - Un Interprète direct simple Supposons que nous souhaitions calculer: Il faudra: - analyser la chaîne et isoler les symboles "3", "+", "4", "*" et "5". Ce travail sera réalisé par un analyseur lexical
- vérifier que l'expression est légale. Par exemple "3++ 5" serait illégal. La vérification sera effectuée par un analyseur syntaxique
- évaluer l'expression: l'expression est transformée en une structure ou un
programme qui évalue le résultat.
Pour l'analyseur lexicale: Pour l'analyse syntaxique: - nous commencerons par utiliser la grammaire simple suivante:
start= expression .
expression= [ '+' | '-' ] term { ( '+' | '-' ) term } .
term= factor { ( '*' | '/' ) factor } .
factor= NUMBER | '(' expression ')' . | |
Sans rentrer dans le détail de ce formalisme, vous noterez que les règles les plus emboîtées sont exécutées en priorité. Dans le cas de l'expression: le terme multiplicatif 2* 3* 4 est évalué en premier, puis l'expression additive 1+ 24. C'est le même principe que les boucles emboîtées:
for pays:= 1 to 10 do
for ville:= 1 to 100 do
recense_population ;
| pour chaque pays, la boucle FOR ville est exécutée entièrement avant
d'incrémenter pour le pays suivant. De même, pour notre grammaire, la multiplication a la précédence sur l'addition. - nous créons les procédures qui analysent l'expression conforme à cette grammaire:
PROCEDURE parse_start;
PROCEDURE parse_expression;
PROCEDURE parse_term;
PROCEDURE parse_factor;
BEGIN
CASE f_symbol_type OF
e_NUMBER_symbol :
read_symbol;
e_opening_parenthesis_symbol :
BEGIN
// -- skip "("
read_symbol;
parse_expression;
check(e_closing_parenthesis_symbol);
// -- skip ")"
read_symbol;
END; // n
ELSE display_error('NUMBER, (');
END; // case
END; // parse_factor
BEGIN // parse_term
parse_factor;
WHILE f_symbol_type IN [e_times_symbol, e_divide_symbol] DO
BEGIN
read_symbol;
parse_factor;
END; // WHILE {
END; // parse_term
BEGIN // parse_expression
IF f_symbol_type IN [e_plus_symbol, e_minus_symbol]
THEN BEGIN
// -- unary "+" and "-"
read_symbol
END; // IF [
parse_term;
WHILE f_symbol_type IN [e_plus_symbol, e_minus_symbol] DO
BEGIN
read_symbol;
parse_term;
END; // WHILE {
END; // parse_expression
BEGIN // parse_start
parse_expression;
END; // parse_start
|
Le parallélisme entre la grammaire et l'appel des procédures PASCAL est immédiat. Nous pouvons générer ce type de code manuellement, ou utiliser un "compilateur de compilateur", ce qui est le cas ici: à partir du texte de la
grammaire, un con-compilateur génère automatiquement le texte ci-dessus. Dans ce texte: - read_symbol est une procédure qui appelle read_symbol de l'analyseur lexical
- f_symbol_type est le type du symbole courant
- check est une procédure qui vérifie que le symbole courant est bien du type souhaité et qui lit le symbole suivant si c'est le cas
- display_error affiche l'erreur
Notez que le texte ci-dessus se contente de vérifier que le texte fourni est conforme à la grammaire. Il n'effectue aucun traitement ou calcul. Pour l'interprétation
- dans le cas de la grammaire simple, l'analyse syntaxique peut être accompagnée d'une évaluation:
- chaque fois que nous trouvons une chaîne numérique nous calculons sa valeur binaire
- ces valeurs numériques sont remontées par les procédures de l'analyseur qui retourne, en final, la valeur numérique:
- voici un exemple pour calculer un terme:
procedure parse_term(var pv_term: Integer);
procedure parse_factor(var pv_factor: Integer);
begin
with p_c_scanner do
begin
case m_symbol_type of
e_integer_symbol :
begin
pv_factor:= StrToInt(m_symbol_string);
read_symbol;
end;
e_opening_parenthesis_symbol :
begin
read_symbol;
parse_expression(pv_factor);
if m_symbol_type= e_closing_parenthesis_symbol
then read_symbol
else display_error('manque )');
end;
else display_error('attend fact: k, var, (: '+ m_symbol_string);
end; // case
end; // with p_c_scanner
end; // parse_factor
var l_save_multiply_operator: t_symbol_type;
l_next_factor: Integer;
begin // parse_term
with p_c_scanner do
begin
parse_factor(pv_term);
while m_symbol_type in [e_times_symbol, e_slash_symbol] do
begin
l_save_multiply_operator:= m_symbol_type;
read_symbol;
parse_factor(l_next_factor);
case l_save_multiply_operator of
e_times_symbol : pv_term:= pv_term* l_next_factor;
e_slash_symbol : pv_term:= pv_term div l_next_factor;
end; // case l_save_multiply_operator
end; // while m_symbol_type
end; // with p_c_scanner
end; // parse_term
|
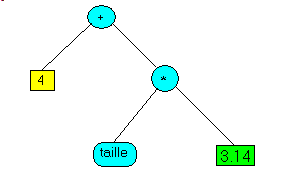
3 - Un interprète plus complexe 3.1 - Objectif Nous allons légèrement compliquer notre interprète. Nous souhaitons calculer:
taille= 5 ;
valeur= 4+ taille* 3.14 ;
superieur= FALSE ;
fini= ( taille * 7 > valeur ) OR superieur ;
possible= NOT (valeur / 17 ) < SIN (- taille) ; | Il faut donc ajouter:
- des opérateurs plus compliqués: "<", "<=" etc
- la notion de variable: nous désignons par un nom une valeur
- plusieurs types de variables: des entiers, des réels, des booléens
- une suite d'instructions d'affectation
- des fonctions prédéfinies, telles que SIN(30), EXP(3, 5)
Voici la grammaire dont nous sommes parti:
start= { assignment } .
assignment= NAME ':=' expression ';' .
expression= simple_expression
[ ('=' | '<>' | '<' | '<=' | '>' | '>=' ) simple_expression ] .
simple_expression= [ '+' | '-' ] term { ('+' | '-' | OR ) term } .
term= factor { ('*' | '/' | DIV | AND ) factor } .
factor= NUMBER | TRUE | FALSE | NAME |
NOT factor | '(' expression ')'
| [ SIN | COS ] '(' expression ')' | EXP '(' expression ',' expression ')' . |
| 3.2 - Principe Dans notre nouvelle version: - l'analyseur lexical est un peu plus complexe, puisqu'il doit à présent gérer le nom des variables, plusieurs types de valeurs littérales.
- l'analyseur syntaxique a été dérivé à nouveau de notre grammaire et ne présente pas de grande nouveauté.
- pour l'évaluation, cela se complique un peu:
- il faut stocker les valeurs de nos variables
- les opérations doivent tenir compte du type des données
Nous avons choisi de séparer l'analyse de l'évaluation: - l'analyseur syntaxique produit un arbre syntaxique
- un évaluateur parcourt cet arbre et stocke les résultats dans une mémoire
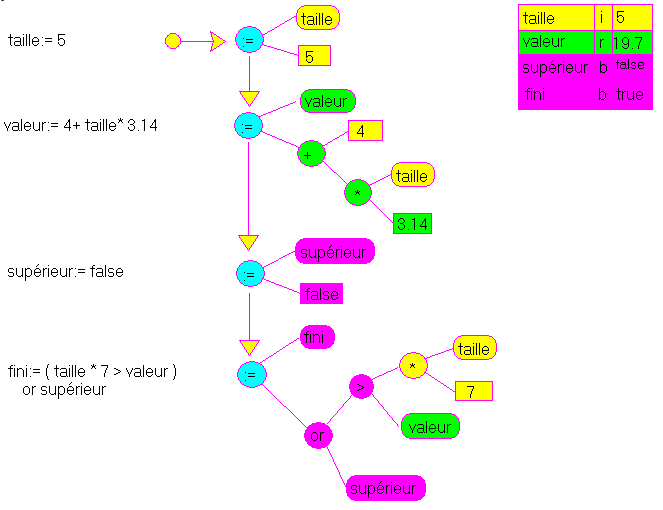
L'arbre syntactique est simplement une représentation symbolique de notre calcul. Pour une expression simple telle que:
notre arbre aurait l'allure suivante:
Si nous évaluons cet arbre de bas en haut, - nous commençons à la racine "+"
- il faut évaluer les deux sous arbres
- la valeur du sous arbre "4" est "4"
- l'autre sous arbre est "*". Il faut évaluer d'abord ses sous-arbres
- supposons que taille ait la valeur 5
- l'autre sous-arbre a la valeur 3.14
le noeud "*" a donc la valeur 15.7
le noeud "+" a alors la valeur 19.7
La suite des affectation est alors stockée dans une simple liste chaînée dont chaque cellule comporte: - le nom de la variable à gauche de ":=" (left hand side, ou lhs)
- l'expression qui calcule la valeur de la variable (right hand side ou rhs)
La suite d'affectations qui suit:
taille= 5 ;
valeur= 4+ taille* 3.14 ;
superieur= FALSE ;
fini= ( taille * 7 > valeur ) OR superieur ; | est alors transformés par notre analyseur syntaxique en:
Pour gérer nos variables: - nous créons une table qui va mémoriser la valeur de chaque variable
- chaque cellule contient
- le nom
- le type (entier, réel, booléen)
- la valeur de la variable
- la structure permet:
- l'ajout
- le stockage du type et de la valeur
- la recherche par nom
Le résultat de notre calcul sera alors la liste des variables avec leur valeur. Pour effectuer ce calcul:
- nous balayons l'arbre syntaxique dans l'ordre des instructions
- si une variable n'existe pas, nous l'allouons dans la table des variables
- l'évaluation de l'expression de droite est effectués, exactement comme pour
notre premier exemple, sauf que:
- si un facteur est un nom de variable, nous allons chercher sa valeur dans la table
- les calculs tiennent compte des types des variables:
- + * etc ne sont permis que pour les valeurs numériques
- AND OR NOT ne sont permis que pour les booléens
- etc
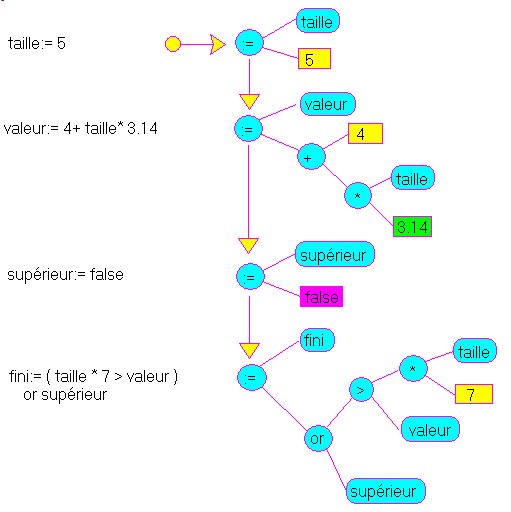
Par exemple, après le début de l'évaluation de la troisième instruction, la
situation serait la suivante: Notez que: - les types et les valeurs des deux premières instructions ont été calculés
- la troisième variable a été allouée, mais comme nous n'avons pas encore évalué la valeur du membre de droite, nous ne connaissons encore ni le type ni la valeur de la variable supérieur
Après l'évaluation des quatre instructions, nous aurions: Lors de l'évaluation, les valeurs sont stockées à la fois dans l'arbre et dans la mémoire des variables. Il faut pouvoir: - stocker la valeur
- lire la valeur
Comme nous devons le faire à la fois pour les noeuds de l'arbre et pour les variables, nous avons crée une classe c_value qui contient:
- le type, défini comme un énuméré (e_integer_type, e_real_type, e_boolean_type)
- des membres m_integer_value, m_real_value, m_boolean_value
- les procédures de lecture (f_integer_value ...) et d'écriture (set_integer_value ...)
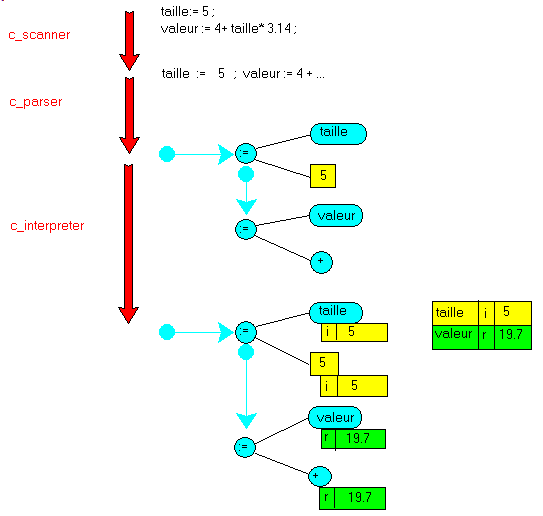
3.3 - Schéma du traitement Notre traitement peut donc être schématisé de la façon suivante:
3.4 - Codage Le projet comporte les unités - u_symbol_definition
- u_c_scanner
- u_c_data_value
- u_c_ast_tree
- u_c_instruction_list
- u_c_parser
- u_c_variable_list
- u_c_interpreter
3.4.1 - Les symboles: u_symbol_definition Cette unité contient la liste des symboles, ainsi que deux tables permettant:
- la conversion entre une ponctuation "+" en son symbole e_plus_symbol
- la conversion d'un mot clé DIV en son symbole e_DIV_symbol
La liste des symboles est la suivante:
TYPE t_symbol_type= (e_unknown_symbol,
e_integer_litteral_symbol, e_real_litteral_symbol,
e_semi_colon_symbol,
e_opening_parenthesis_symbol, e_closing_parenthesis_symbol,
e_plus_symbol, e_minus_symbol, e_times_symbol, e_divide_symbol,
e_less_symbol, e_greater_symbol, e_equal_symbol,
e_becomes_symbol,
e_less_or_equal_symbol, e_greater_or_equal_symbol,
e_different_symbol,
e_key_word_start,
e_AND_symbol, e_OR_symbol, e_NOT_symbol, e_DIV_symbol,
e_TRUE_symbol, e_FALSE_symbol,
e_SIN_symbol, e_COS_symbol, e_EXP_symbol,
e_identifier_symbol,
e_last_symbol);
|
3.4.2 - L'analyseur lexical: u_c_lexical
La classe a la même structure que l'analyseur lexical simple, sauf qu'il faut analyser plus finement le source. Voici la procédure principale:
procedure c_scanner.read_symbol;
const k_blanks= [' ', chr(9)];
k_returns= [chr(13), chr(10), chr(26)];
k_blanks_returns= k_blanks+ k_returns;
k_letters= ['a'..'z', 'A'..'Z'];
k_accents= ['à', 'â', 'é', 'ç', 'ê', 'è', 'î', 'ô', 'ù', 'û'];
k_digits= ['0'..'9'];
k_identifiers= k_letters+ k_accents+ k_digits+ ['_'];
procedure skip_blanks;
var l_start_index: Integer;
begin
l_start_index:= m_buffer_index;
while (m_buffer_index< m_buffer_size) and (m_pt_buffer[m_buffer_index] in k_blanks_returns) do
inc(m_buffer_index);
end; // skip_blanks
procedure get_number;
var l_start_index: Integer;
begin
l_start_index:= m_buffer_index;
m_symbol_type:= e_integer_litteral_symbol;
while (m_buffer_index< m_buffer_size) and (m_pt_buffer[m_buffer_index] in ['0'..'9']) do
inc(m_buffer_index);
// -- decimal part ?
if (m_buffer_index< m_buffer_size) and (m_pt_buffer[m_buffer_index]= '.') and (m_pt_buffer[m_buffer_index+ 1]<> '.')
then begin
m_symbol_type:= e_real_litteral_symbol;
inc(m_buffer_index);
while (m_buffer_index< m_buffer_size) and (m_pt_buffer[m_buffer_index] in ['0'..'9']) do
inc(m_buffer_index);
end;
// -- exponent part
if (m_buffer_index< m_buffer_size) and (m_pt_buffer[m_buffer_index]= 'e') or (m_pt_buffer[m_buffer_index]= 'E')
then begin
m_symbol_type:= e_real_litteral_symbol;
inc(m_buffer_index);
if (m_buffer_index< m_buffer_size) and (m_pt_buffer[m_buffer_index]= '+') or (m_pt_buffer[m_buffer_index]= '-')
then inc(m_buffer_index);
while (m_buffer_index< m_buffer_size) and (m_pt_buffer[m_buffer_index] in ['0'..'9']) do
inc(m_buffer_index);
end;
m_symbol_string:= f_extract_string_start_end(l_start_index, m_buffer_index- 1);
end; // get_number
procedure get_identifier;
var l_start_index: Integer;
begin
l_start_index:= m_buffer_index;
Inc(m_buffer_index);
while (m_buffer_index< m_buffer_size) and (m_pt_buffer[m_buffer_index] in k_identifiers) do
inc(m_buffer_index);
m_symbol_string:= f_extract_string_start_end(l_start_index, m_buffer_index- 1);
m_symbol_type:= f_key_word_symbol(m_symbol_string);
end; // get_identifier
procedure get_operator_1(p_operator_type: t_symbol_type);
begin
m_symbol_type:= p_operator_type;
m_symbol_string:= m_pt_buffer[m_buffer_index];
Inc(m_buffer_index, 1);
end; // get_operator_1
procedure get_operator_2(p_operator_type: t_symbol_type);
begin
m_symbol_type:= p_operator_type;
m_symbol_string:= m_pt_buffer[m_buffer_index]+ m_pt_buffer[m_buffer_index+ 1];
Inc(m_buffer_index, 2);
end; // get_operator_2
procedure get_operator;
var l_operator: Char;
begin
l_operator:= m_pt_buffer[m_buffer_index];
Inc(m_buffer_index);
m_symbol_string:= l_operator;
m_symbol_type:= g_1_character_punctuations[l_operator];
if m_symbol_type= e_unknown_symbol
then display_error('unknown');
end; // get_operator
begin // f_c_symbol
m_symbol_type:= e_unknown_symbol;
m_symbol_string:= '';
skip_blanks;
if m_buffer_index< m_buffer_size
then begin
case m_pt_buffer[m_buffer_index] of
'a'..'z', 'A'..'Z', '_',
'à', 'â', 'é', 'ç', 'ê', 'è', 'î', 'ô', 'ù', 'û': get_identifier;
'0'..'9' : get_number;
'/' : get_operator_1(e_divide_symbol);
':' : if (m_buffer_index< m_buffer_size) and (m_pt_buffer[m_buffer_index+ 1]= '=')
then get_operator_2(e_becomes_symbol)
else display_error('unknown_symbol');
'<' : if (m_buffer_index< m_buffer_size) and (m_pt_buffer[m_buffer_index+ 1]= '=')
then get_operator_2(e_less_or_equal_symbol)
else
if (m_buffer_index< m_buffer_size) and (m_pt_buffer[m_buffer_index+ 1]= '>')
then get_operator_2(e_different_symbol)
else get_operator_1(e_less_symbol);
'>' : if (m_buffer_index< m_buffer_size) and (m_pt_buffer[m_buffer_index+ 1]= '=')
then get_operator_2(e_greater_or_equal_symbol)
else get_operator_1(e_greater_symbol);
'=', '+', '-', '*' ,
';', ',', '(', ')' : get_operator;
else
display_error('unknown_symbol');
end; // case
end
else m_symbol_type:= e_last_symbol;
end; // read_symbol
| Prenons les deux instructions suivantes comme example:
taille= 5 ;
valeur= 4+ taille* 3.14 ; |
la trace d'analyse est la suivante: 6 >taille< identifier
8 >:=< becomes
10 >5< integer_litteral
12 >;< semi_colon
20 >valeur< identifier
22 >:=< becomes
24 >4< integer_litteral
25 >+< plus
32 >taille< identifier
33 >*< times
38 >3.14< real_litteral
40 >;< semi_colon
44 >< last |
3.4.3 - L'arbre syntaxique: u_c_ast_tree
Les membres de droite (les expressions à droite de ":=") sont représentées par les classes suivantes:
type c_node= class(c_basic_object)
m_c_left_node, m_c_right_node: c_node;
m_node_type: t_symbol_type;
m_c_data_value: c_data_value;
Constructor create_node(p_name: String; p_node_type: t_symbol_type);
function f_display_node: String; Virtual;
procedure display_node;
procedure display_node_data_value;
Destructor Destroy; Override;
end; // c_node
c_identifier_node= class(c_node)
Constructor create_identifier_node(p_name: String;
p_node_type: t_symbol_type);
end; // c_identifier_node
c_litteral_node= class(c_node)
Constructor create_litteral_node(p_name: String;
p_node_type: t_symbol_type);
end; // c_litteral_node
c_binary_operation_node= class(c_node)
Constructor create_binary_operation_node(p_name: String;
p_node_type: t_symbol_type;
p_c_operand_one, p_c_operand_two: c_node);
end; // c_operation_node
c_unary_operation_node= class(c_node)
Constructor create_unary_operation_node(p_name: String;
p_node_type: t_symbol_type; p_c_operand: c_node);
end; // c_operation_node
c_function_node= Class(c_node)
Constructor create_function_node(p_name: String;
p_node_type: t_symbol_type; p_c_parameter_one, p_c_parameter_two: c_node);
end; // c_function_node
| Les membres de c_node sont: - m_name (situé dans c_basic_object) contient le symbole lu:
- pour les valeur littérales, cette STRING permettra de récupérer la
valeur binaire
- pour les variables, le nom permettra de rechercher la valeur de la variable dans la table des variables
- m_node_type permettra de tester le type d'opération (plutôt que de comparer des chaînes)
- m_c_data_value ne sera utilisé que lors de l'évaluation des valeur
Nous avons crée des types différents pour chaque catégorie syntaxique, mais en fait les données sont toutes dans c_node.
3.5 - La liste des instructions: u_c_instruction_list Les classes utilisées pour représenter la liste d'instruction est la suivante:
type c_instruction= Class(c_basic_object)
m_c_next_instruction: c_instruction;
m_c_rhs_expression: c_node;
Constructor create_instruction(p_name: String; p_c_rhs_expression: c_node);
procedure display_instruction;
procedure display_instruction_data_value;
function f_display_instruction: String;
Destructor Destroy; Override;
end; // c_instruction
c_instruction_list= Class(c_basic_object)
m_c_first_instruction: c_instruction;
m_instruction_count: Integer;
Constructor create_instruction_list(p_name: String);
function f_instruction_count: Integer;
procedure add_instruction(p_c_instruction: c_instruction);
procedure display_instruction_list;
procedure display_instruction_list_data_value;
Destructor Destroy; Override;
end; // c_instruction_list
| Nous avons utilisé une liste chaînée, car c'est la classe que nous avions utilisé pour présenter le pattern INTERPRETER des Gof. Nous utiliserions actuellement plutôt une tStringList pour ce type de codage.
Dans les deux cas, chaque c_instruction contient: - dans m_name le nom de la variable à gauche de ":="
- dans m_c_rhs_expression la racine de l'arbre syntaxique correspondant au membre à droite de ":="
3.5.1 - L'analyse syntaxique: u_c_parser La procédure read_symbol simple (sans la génération de l'arbre) est la suivant:
PROCEDURE parse_start;
PROCEDURE parse_assignment;
PROCEDURE parse_expression;
PROCEDURE parse_simple_expression;
PROCEDURE parse_term;
PROCEDURE parse_factor;
BEGIN
CASE f_symbol_type OF
e_NUMBER_symbol :
read_symbol;
e_TRUE_symbol :
read_symbol;
e_FALSE_symbol :
read_symbol;
e_IDENTIFIER_symbol :
read_symbol;
e_NOT_symbol :
BEGIN
read_symbol;
parse_factor;
END; // n
e_opening_parenthesis_symbol :
BEGIN
read_symbol;
parse_expression;
check(e_closing_parenthesis_symbol);
read_symbol;
END; // n
e_SIN_symbol, e_COS_symbol :
BEGIN
read_symbol;
check(e_opening_parenthesis_symbol);
read_symbol;
parse_expression;
check(e_closing_parenthesis_symbol);
read_symbol;
END; // n
e_EXP_symbol :
BEGIN
read_symbol;
check(e_opening_parenthesis_symbol);
read_symbol;
parse_expression;
check(e_comma_symbol);
read_symbol;
parse_expression;
check(e_closing_parenthesis_symbol);
read_symbol;
END; // n
ELSE display_error('NUMBER, TRUE, FALSE, NAME, NOT, (, EXP');
END; // case
END; // parse_factor
BEGIN // parse_term
parse_factor;
WHILE f_symbol_type IN k_multiplication_symbols DO
BEGIN
read_symbol;
parse_factor;
END; // WHILE {
END; // parse_term
BEGIN // parse_simple_expression
IF f_symbol_type IN k_addition_symbols
THEN read_symbol;
parse_term;
WHILE f_symbol_type IN k_addition_symbols DO
BEGIN
read_symbol;
parse_term;
END; // WHILE {
END; // parse_simple_expression
BEGIN // parse_expression
parse_simple_expression;
IF f_symbol_type IN k_comparison_symbols
THEN BEGIN
read_symbol;
parse_simple_expression;
END; // IF [
END; // parse_expression
BEGIN // parse_assignment
check(e_IDENTIFIER_symbol);
read_symbol;
check(e_becomes_symbol);
read_symbol;
parse_expression;
check(e_semi_colon_symbol);
read_symbol;
END; // parse_assignment
BEGIN // parse_start
WHILE f_symbol_type= e_IDENTIFIER_symbol DO
parse_assignment;
END; // parse_start
|
Nous ajoutons alors manuellement la création des noeuds de l'arbre syntaxique. Le code pour les expressions, par exemple, est le suivant:
function f_c_parse_expression: c_node;
function f_c_parse_simple_expression: c_node;
function f_c_parse_term: c_node;
function f_c_parse_factor: c_node;
var l_function_name: String;
l_function_type: t_symbol_type;
l_c_operand_one: c_node;
BEGIN
CASE m_symbol_type OF
e_integer_litteral_symbol :
BEGIN
Result:= c_litteral_node.create_litteral_node(m_symbol_string, e_integer_litteral_symbol);
read_symbol;
END;
e_real_litteral_symbol :
BEGIN
Result:= c_litteral_node.create_litteral_node(m_symbol_string, e_real_litteral_symbol);
read_symbol;
END;
e_TRUE_symbol :
BEGIN
Result:= c_litteral_node.create_litteral_node(m_symbol_string, e_TRUE_symbol);
read_symbol;
END;
e_FALSE_symbol :
BEGIN
Result:= c_litteral_node.create_litteral_node(m_symbol_string, e_FALSE_symbol);
read_symbol;
END;
e_IDENTIFIER_symbol :
BEGIN
Result:= c_identifier_node.create_identifier_node(m_symbol_string, e_identifier_symbol);
read_symbol;
END;
e_NOT_symbol :
BEGIN
read_symbol;
Result:= c_unary_operation_node.create_unary_operation_node('NOT',
e_NOT_symbol, f_c_parse_factor);
END; // n
e_opening_parenthesis_symbol :
BEGIN
read_symbol;
Result:= f_c_parse_expression;
check(e_closing_parenthesis_symbol);
read_symbol;
END;
e_SIN_symbol, e_COS_symbol, e_EXP_symbol :
BEGIN
l_function_name:= m_symbol_string;
l_function_type:= m_symbol_type;
read_symbol;
check(e_opening_parenthesis_symbol);
read_symbol;
if l_function_type= e_EXP_symbol
then begin
l_c_operand_one:= f_c_parse_expression;
check(e_comma_symbol);
read_symbol;
Result:= c_function_node.create_function_node(l_function_name,
e_EXP_symbol, l_c_operand_one, f_c_parse_expression);
end
else Result:= c_function_node.create_function_node(l_function_name,
l_function_type, f_c_parse_expression, Nil);
check(e_closing_parenthesis_symbol);
read_symbol;
END; // n
ELSE display_error('NUMBER, TRUE, FALSE, NAME, NOT, (, EXP');
END; // case
END; // f_c_parse_factor
var l_operation_string: String;
l_operation_symbol: t_symbol_type;
BEGIN // f_c_parse_term
Result:= f_c_parse_factor;
WHILE m_symbol_type IN k_multiplication_symbols DO
BEGIN
l_operation_string:= m_symbol_string;
l_operation_symbol:= m_symbol_type;
read_symbol;
Result:= c_binary_operation_node.create_binary_operation_node(l_operation_string,
l_operation_symbol, Result, f_c_parse_factor);
END; // WHILE {
END; // f_c_parse_term
var l_operation_string: String;
l_operation_symbol: t_symbol_type;
BEGIN // f_c_parse_simple_expression
IF m_symbol_type IN k_addition_symbols
THEN BEGIN
l_operation_string:= m_symbol_string;
l_operation_symbol:= m_symbol_type;
read_symbol;
Result:= c_unary_operation_node.create_unary_operation_node(
l_operation_string, l_operation_symbol, f_c_parse_term);
END // IF [
else Result:= f_c_parse_term;
WHILE m_symbol_type IN (k_addition_symbols) DO
BEGIN
l_operation_string:= m_symbol_string;
l_operation_symbol:= m_symbol_type;
read_symbol;
Result:= c_binary_operation_node.create_binary_operation_node(l_operation_string,
l_operation_symbol, Result, f_c_parse_term);
END; // WHILE {
END; // f_c_parse_simple_expression
var l_comparison_string: String;
l_comparison_symbol: t_symbol_type;
BEGIN // f_c_parse_expression
Result:= f_c_parse_simple_expression;
IF m_symbol_type IN k_comparison_symbols
THEN BEGIN
l_comparison_string:= m_symbol_string;
l_comparison_symbol:= m_symbol_type;
read_symbol;
Result:= c_binary_operation_node.create_binary_operation_node(l_comparison_string,
l_comparison_symbol, Result, f_c_parse_simple_expression);
END; // IF [
END; // f_c_parse_expression
|
Nous avons choisi ici d'utiliser les fonctions, ce qui évite le passage de paramètres VAR pour remonter les valeurs aux procédure appelantes. La trace indentée de l'analyze des deux instructions ci-dessus est la suivante:
|> parse
| > assignment taille taille
| > expression 5
| > simple_expression 5
| > term 5
| > factor 5
| < factor ;
| < term ;
| < simple_expression ;
| < expression ;
| < assignment valeur
| > assignment valeur valeur
| > expression 4
| > simple_expression 4
| > term 4
| > factor 4
| < factor +
| < term +
| > term taille
| > factor taille
| < factor *
| > factor 3.14
| < factor ;
| < term ;
| < simple_expression ;
| < expression ;
| < assignment
|< parse
|
3.5.2 - Représentation des valeurs: u_c_data_value Pour stocker nos trois types de données, nous avons utilisé la classe suivante:
type t_data_type= (e_unknown_type, e_integer_type, e_real_type, e_boolean_type);
c_data_value= Class(c_basic_object)
m_data_type: t_data_type;
m_real_value: Double;
m_integer_value: Integer;
m_boolean_value: Boolean;
constructor create_data_value(p_name: String);
function f_display_data_value: String;
function f_display_data_value_and_litteral: String;
function f_integer_value: Integer;
function f_real_value: Double;
function f_boolean_value: Boolean;
procedure set_integer_value(p_integer_value: Integer);
procedure set_real_value(p_real_value: Double);
procedure set_boolean_value(p_boolean_value: Boolean);
end; // c_data_value
|
Cette classe permet de stocker et lire indifféremment des type entier, réel et booléen. Elle est utilisée: - dans chaque noeud de l'arbre syntaxique
- dans la liste des variables
3.5.3 - Le stockage des variables: u_c_variable_list Les variables sont allouées et leur valeur stockées dans les classes suivantes:
type c_variable_list= Class(c_basic_object)
m_c_variable_list: tStringList;
Constructor create_variable_list(p_name: String);
function f_variable_count: Integer;
function f_c_variable(p_variable_index: Integer): c_data_value;
function f_index_of(p_variable_name: String): Integer;
function f_c_add_variable(p_variable_name: String): c_data_value;
procedure display_variable_list;
procedure display_variable_list_data_value;
Destructor Destroy; Override;
end; // c_variable_list
| Il s'agit ici simplement de l'encapsulation d'une tStringList: - le nom permet la recherche par nom
- la liste Objects contient un pointeur vers un objet de type c_data_value
3.5.4 - Le calcul des valeurs: u_c_interpreter L'interprète est représenté par la class suivante:
type c_interpreter= class(c_basic_object)
m_trace_interpreter: Boolean;
Constructor create_interpreter(p_name: string);
procedure trace_interpreter(p_text: String);
procedure interpret(p_c_instruction_list: c_instruction_list;
p_c_variable_list: c_variable_list);
Destructor Destroy; Override;
end; // c_interpreter
|
Puis:
La trace indentée de l'évaluation des deux instructions ci-dessus est la suivante:
|> evaluate taille :=
| allocate "taille"
| > expression 5
| set_integer: "5" <-- 5
| < expression 5
| set_integer: "taille" <-- 5
|< evaluate taille
|
|> evaluate valeur :=
| allocate "valeur"
| > expression +
| > expression *
| > expression 3.14
| set_real: "3.14" <-- 3.14
| < expression 3.14
| > expression taille
| set_integer: "taille" <-- 5
| < expression taille
| set_real: "*" <-- 15.7
| < expression *
| > expression 4
| set_integer: "4" <-- 4
| < expression 4
| set_real: "+" <-- 19.7
| < expression +
| set_real: "valeur" <-- 19.7
|< evaluate valeur
| Et l'affichage du résultat final (la table des variables) fournit: taille (integer) [5]
valeur (real) [19,7] |
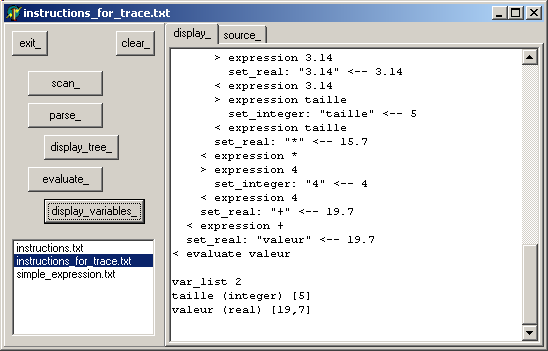
3.5.5 - Le projet complet Le projet complet permet - la séléction d'un source dans une tFileListBox
- l'analyse syntaxique avec trace
- l'analyse lexicale avec trace
- l'affichage de l'arbre syntaxique
- l'évaluation avec trace
- l'affichage des résultat
Voici une vue après affichage des variables:
4 - Améliorations Nos deux programmes n'ont aucune prétention: ils présentent deux façon d'analyser et d'évaluer des expressions. Parmi les nombreuses améliorations, citons:
- nous aurions pu utiliser un Variant pour stocker nos données. Le variant contient en effet un type (entier, booléen...) et sa valeur. Mais les variants sont des bestioles maléfiques venu d'un âge jurassique et que nous
évitons d'utiliser chaque fois que c'est possible.
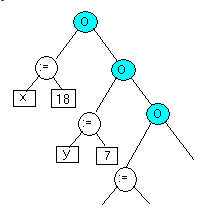
- nous avons utilisé un arbre pour les expressions et une liste pour les instructions. Nous aurions pu utiliser un arbre binaire uniquement: le noeud
gauche désigne l'instruction et le noeud droit l'instruction suivante.
En regardant de plus près, notre schéma a déjà l'air d'un arbre: il suffit de l'incliner de 45 degrés et d'effectuer une symétrie.
Une suite d'instructions d'affectation pourrait ainsi être représentée par: La représentation par deux classes séparées représente plus fidèlement les données. L'utilisation d'un arbre (pour toute la grammaire Pascal
d'ailleurs) évite la multiplication des types, en supposant que le programmeur comprenne que, dans certaines circonstances, m_c_left_node signifie "instruction suivante", ou encore "paramètre suivant", "variable de la liste suivante" etc.
- notre interprète comporte énormément d'hypothèses cachées:
- les variables doivent toujours figurer à gauche de ":=" avant de pouvoir être utilisées à droite de ":=". Ce qui revient à "déclarer avant d'utiliser"
- le type des données est déduit des valeurs littérales. Nous avons juste appliqué une petite promotion de types numériques (un entier peut figurer dans une expression réelle: taille* 3.14)
- les règles de compatibilité d'affectation sont aussi implicites
Bien sûr nous aurions pu "typer" les noms (i_taille, r_valeur, b_fini) ou même introduire de véritables déclarations VAR.
En fait, il faudrait définir un "language manual" en bonne et due forme. La modestie du projet ne le justifie pas. - dans l'arbre, les valeurs numériques sont calculées au fur et à mesure.
C'est pourquoi chaque noeud contient une copie du type et de la valeur. La table des variables contient la dernière valeur calculée.
Notre interprète n'est en effet ni un tableur ni un langage de propagation
de contraintes. Mathematica et Excel sont encore assez loin, semble-t-il - nous avons essayé de récupérer toutes les erreurs possibles. S'il y a une lesson que nous avons bien retenu pour les projets d'interprète est de
remonter les erreurs aussitôt que possible. D'autant que nos programmes sont agressivement récursifs (parce que la grammaire l'est: expression -> terme -> facteur -> expression).
Nous pourrions améliorer la présentation des erreurs: - affichage du texte complet avec curseur SUR l'erreur
- possibilité de continuer la compilation en dépit d'erreur intermédiaires
- nous sommes passés directement de l'arbre syntaxique à l'interprétation. Nous aurions pu utiliser des "peignages" successifs de l'arbre pour:
- analyser les types
- générer du code intermédiaire
- les noeuds de notre arbre sont assez pauvres: c_node contient tout ce qu'il faut. En fait, si nous avions utilisé des techniques de vérification, d'allocation etc, nous aurions pu placer dans c_litteral_node ou
c_function_node des données propres à ces noeuds-là
Dans notre compilateur actuel: - nous utilisons les structures canoniques de Wirth:
- une structure qui gère les identificateurs (k_total, t_date,
c_ecriture, g_c_journal)
- une structure qui gère les définitions de type (ARRAY[1..5] OF Integer, STRING[21])
- une pile des attributs (les identificateurs et types connus à un niveau
syntactique donné)
- un arbre syntaxique qui synthétise le source
- c_scanner débite le source en symboles
- c_parser construit l'arbre syntaxique correspondant au programme, ainsi que la pile des attributs
- c_generator récupère l'arbre et les attributs et:
- termine les vérifications de type
- calcule les addresses des variables (allocation)
- génère de l'assembleur x386 (Pentium) sous forme tokenisé (ADD est codé
sous forme d'un énuméré e_add_codop etc)
- c_assembler_386 utilise la liste des instructions assembleur pour générer directement le binaire (PUN pour les unités et EXE pour le programme).
5 - Télécharger le source Le code complet des deux interprètes, ainsi que les classes utilitaires que je n'ai pas détaillées (u_display, u_c_text_file etc) sont regroupés dans deux
.ZIP, qui contiennent tous les sources. Ces .ZIP contiennent des chemins RELATIFS. Par conséquent: - créez un répertoire n'importe où sur votre machine
- téléchargez en cliquant les liens ci-dessous
- placez le .ZIP dans votre répertoire
- dézippez et les sous-répertoires nécessaires seront créés
- compilez et exécutez
Au niveau sécurité: - les .ZIP:
- ne modifient pas votre PC (pas de changement de la Base de Registre, d'écrasement de DLL ou autre .BAT). Aucune modification de répertoire ou de contenu de répertoire ailleurs que dans celui où vous dézippez
- ne contiennent aucun programme qui s'exécuterait à la décompression (.EXE, .BAT, .SCR ou autre .VXD) ou qui seraient lancés plus tard (reboot)
- passez-les à l'antivirus avant décompression si vous êtes inquiets.
- les programmes eux-mêmes ne changent pas la base de registre et ne modifient aucun autre répertoire de votre machine
- pour supprimer le projet, effacez simplement le répertoire.
Voici les liens:
Comme d'habitude: - nous vous remercions de nous signaler toute erreur, inexactitude ou problème de téléchargement en envoyant un e-mail à jcolibri@jcolibri.com. Les corrections
qui en résulteront pourront aider les prochains lecteurs
- tous vos commentaires, remarques, questions, critiques, suggestion d'article, ou mentions d'autres sources sur le même sujet seront de même
les bienvenus à jcolibri@jcolibri.com.
- plus simplement, vous pouvez taper (anonymement ou en fournissant votre e-mail pour une réponse) vos commentaires ci-dessus et nous les envoyer en
cliquant "envoyer" :
- et si vous avez apprécié cet article, faites connaître notre site,
ajoutez un lien dans vos listes de liens ou citez-nous dans vos blogs ou réponses sur les messageries. C'est très simple: plus nous aurons de visiteurs et de références Google, plus nous écrirons d'articles.
6 - Références Vous pouvez aussi consulter: - Niklaus WIRTH
- le compilateur P4 de Wirth.
- Florian Klaempfl - http://www.freepascal.org/
- Free Pascal Compiler (alias FPK)
un compilateur Pascal complet: - compatible Delphi en principe
- de nombreuses machines cible (Linux, Windows, Dos, Pam OS, Mac etc)
- génère du binaire pour toutes ces cibles
- Frank PISSOTE - http://www.pascaland.org/
- une base exhaustive de tous les compilateurs Pascal
- Design patterns: les patterns: Facade et Interpreter sont utilisés dans le livre GOF pour gérer des interprètes
- Alix ALIX
- le compilateur Nano Pascal
- Pascalissime 15 et 16
principe de la compilation et machine à pile
- Alix ALIX
- Le con-compilateur Nano Pascal
- Pascalissime 29, 31, 35
un compilateur de compilateur (ebnf -> analyseur syntaxique)
- Pierre LUCAS
- Alain MAURIN
- Etude de Fonctions
- Pascalissime 30, 32, 33, 34
- John COLIBRI
GOF Design Pattern
Le codage Delphi de Facade et Interpreter - présente deux autres petits interprètes
Et naturellement, en allant sur Google, et en tapant des mots clés tels que "interpreter", "compiler", "Pascal", "AST" vous ramènerez d'autres programmes.
7 - L'auteur
John COLIBRI est passionné par le développement Delphi et les applications de Bases de Données. Il a écrit de nombreux livres et articles, et partage son temps entre le développement de projets (nouveaux projets, maintenance, audit, migration BDE, migration Xe_n, refactoring) pour ses clients, le
conseil (composants, architecture, test) et la
formation. Son site contient des articles
avec code source, ainsi que le programme et le calendrier des stages de formation Delphi, base de données, programmation objet, Services Web, Tcp/Ip et
UML qu'il anime personellement tous les mois, à Paris, en province ou sur site client.
|