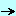|
Moteur de Recherche CGI - John COLIBRI. |
- résumé : un programme CGI retourne les pages correspondant à une recherche textuelle parmi les pages de votre site Web
- mots clé : recherche textuelle - Boyer Moore Horspool - FindFirst,
FindNext - évaluateur d'expression booléennes - CGI
- logiciel utilisé : Windows XP, Delphi 6.0
- matériel utilisé : Pentium 1.400Mhz, 256 M de mémoire, 140 G disque
- champ d'application : Delphi 1 à 2005 sur Windows, Kylix
- niveau : développeur Delphi
- plan :
1 - Introduction
Le moteur de recherche utilisé jusqu'en décembre 2005 utilisait une base de mots clés: - pour chaque article, nous ajoutions une liste de mots considérés comme pertinents
- l'utilisateur tapait une requête dans une Forme CGI, telle que "Delphi AND Interbase"
- le programme analysait la table des mots clés, et un interprète trouvait les pages correspondant à la recherche
- le programme retournait la page des liens vers les pages du site satisfaisant la requête
Il y a deux inconvénients à cette technique: - nous devions rédiger la liste des mots clés pour chaque nouvelle page
- certaines requêtes correspondant à des phrases complètes, telles que "Delphi 2005" ne pouvaient être formulées (il fallait demander "Delphi AND 2005", ce qui n'est pas la même chose)
Nous avons publié sur notre site us The Coliget Search Engine le source d'un moteur de recherche textuelle sur les
fichiers d'un répertoire. Nous allons ici adapter le programme pour qu'il réponde à des requêtes formulées dans une Forme CGI.
2 - Le fonctionnement du moteur
2.1 - Architecture Le fonctionnement est très simple: - l'utilisateur tape sa requête dans un formulaire Web:
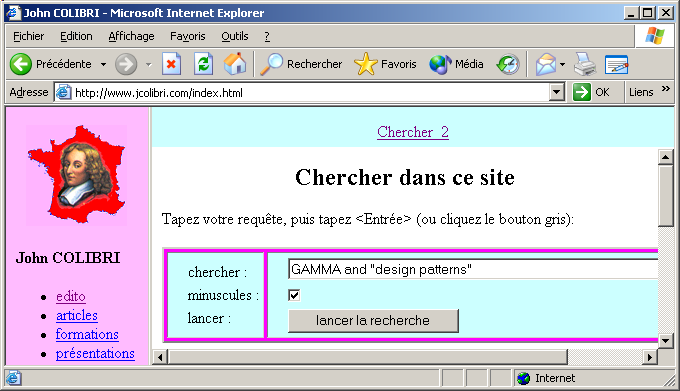
- le serveur de notre site charge en mémoire le moteur que nous allons présenter (le "script cgi")
- ce programme:
- récupère la requête et la débarrasse des artifices CGI
- extrait les chaînes littérales de la requête
- charge une à une les pages de notre site et recherche si le texte de la page satisfait la requête
- construit une page réponse et la renvoie à l'utilisateur:
Examinons ces étapes:
2.2 - Analyse de la requête Il s'agit simplement de lire le fichier d'entrée par Readln, puis de supprimer les artifices liés à la syntaxe CGI ("+", "%", "&" etc)
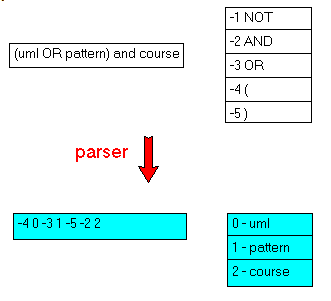
Le résultat est une chaîne identique à celle qu'a tapé l'utilisateur Dans l'exemple précédent: - l'utilisateur a tapé:
|
GAMMA and "design patterns" | en cochant "minuscules" - le Serveur Web envoie au CGI:
|
q=GAMMA+and+%22design+patterns%22&minuscule=on& | - l'analyseur retourne:
GAMMA and "design patterns"
minuscules True |
2.3 - Evaluation de la requête Nous devons - analyser la requête
- pour chaque page de notre site
- charger la page
- tester si son contenu satisfait la requête
Pour accélérer l'évaluation de la requête, nous tokenisons cette requête:
- une tStringList contient les chaînes littérales
- un tableau d'entiers contient
- les indices des chaînes littérales
- des valeurs négatives pour les opérateurs et ponctuations (NOT AND OR ())
Voici un exemple:
2.4 - Analyseur lexical
La tokenisation est effectuée par un analyseur lexical des plus simples: il sépare simplement - les mots clé NOT AND OR
- les ponctuations ( )
- les littéraux uml ou "design pattern"
L'analyseur lexical renvoie un Booléen qui permet d'interrompre le traitement si les symboles tapés sont illégaux.
2.5 - Analyse Syntaxique Avant de lancer le moteur sur la lecture des pages, nous vérifions une fois que
la syntaxe est correcte: Cette vérification de syntaxe se fait par une simple descente récursive en
signalant les problèmes.
2.6 - Chargement des pages Les pages sont recherchées en utilisant simplement FindFirst et FindNext, et le texte charge dans une String
2.7 - Evaluation de la requête sur une page L'évaluation se fait: - en effectuant une descente récursive sur la requête tokenisée
- lorsqu'un token est un littéral, nous effectuons une recherche dans le texte
de la page: le littéral est présent ou non dans le texte
- l'évaluateur combine alors les booléen pour fournir en final le résultat
La recherche dans le texte pourrait être effectuée par Pos, mais pour
accélérer une peu la recherche, nous avons utilisé un algorithme de Boyer Moore Horspool.
Le résultat de cette évaluation sur toutes les pages est une liste de pages comportant pour chacune:
2.8 - Construction du résultat
Nous avons deux types de résultats possibles - les erreurs de syntaxe
- la liste des pages correspondant à la recherche
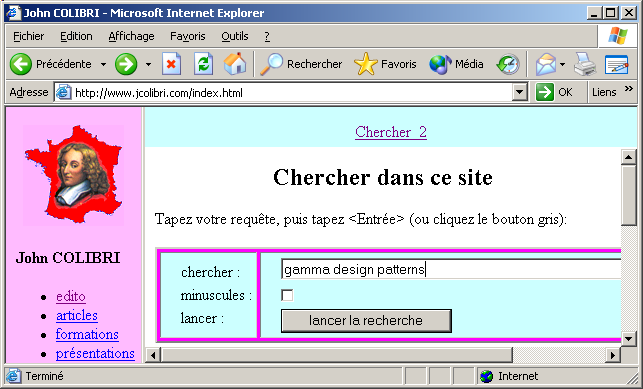
Pour les erreurs, nous retournons la requête en coloriant en rouge la partie
qui pose problème. Voici un exemple: - la requête incorrecte est:
- et voici la réponse du berger à la bergère:
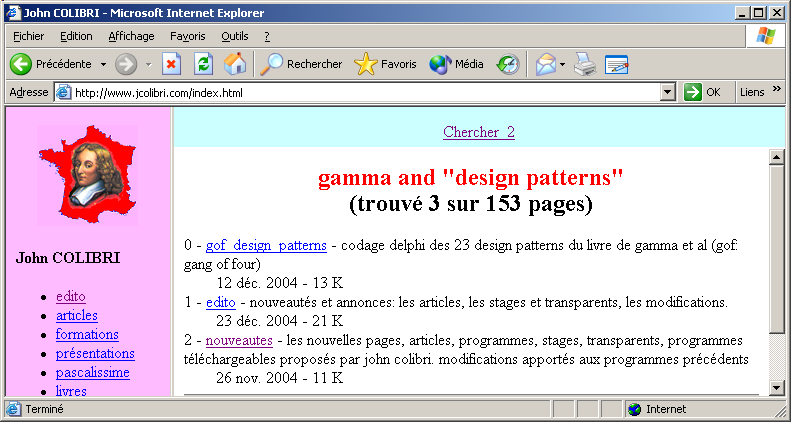
Voici le retour d'une question correcte: - pour la recherche "GAMMA and "design patterns"
- la réponse affiche:
- et le résumé a été récupéré dans le fichier .HTML qui contenait:
<HTML>
<HEAD>
<TITLE>jColibri: Gang of Four Design Patterns</TITLE>
<META http-equiv="Content-Type" content="text/html;
charset=iso-8859-1">
<META http-equiv="CONTENT-LANGUAGE" content="French">
<META http-equiv="VW96.OBJECT TYPE" content="Archive">
<META name="TITLE" content="John COLIBRI">
<META name="DESCRIPTION" content="codage Delphi des 23 Design Patterns du livre de GAMMA et al (gof: Gang of Four)">
<META name="KEYWORDS" content="Design Patterns,Patrons de Conception,Gof,Gang of Four,Erich GAMMA,Richard HELM,Ralph JOHNSON,John |
3 - Le Programme Delphi 3.1 - Organisation des classes Pour le programme CGI, nous avons créé - des unités qui dupliquent nos utilitaires classiques d'analyse de chaînes,
de répertoire, de manipulation de chemins etc. Ces unités ont simplement été débarrassé de toutes référence à des composants visuels de la VCL (tMemo etc). Ces unités n'offrent aucune difficulté
- des unités pour le traitement CGI pur (traitement des variables d'environnement etc). Ces unités ont déjà été présentées dans notre article sur les CGI
- des unités propre à la recherche: analyse lexicale, syntaxique, évaluation,
pages résultat
Pour la recherche: - c_text_searcher encapsule la recherche textuelle d'une chaîne dans une String (BMH dans notre cas)
- c_site_searcher utilise FindFirst et FindNext pour trouver les pages .HTML de notre site
- c_cgi_request_evaluator contient l'évaluateur lexical et l'évaluateur syntaxique
- c_cgi_result_page_list gère la liste des pages correctes et leurs paramètres
- c_cgi_html_page_builder calcule la page d'erreur ou la page de résultats en utilisant la liste de pages
L'unité principale, u_cgi_coliget_search contient une seule procédure qui gère l'ensemble: - lecture et analyse de la requête reçue de serveur
- tokenisation et vérification de la requête
- chargement et analyse de chaque page, avec construction de la liste des pages correctes
- construction de la page résultat HTML
- envoi de la page résultat vers le serveur
3.2 - c_text_searcher
La classe est définie par:
c_text_searcher= class(c_basic_object)
m_text_to_search: String;
m_text_length: Integer;
m_pattern_to_find: String;
m_pattern_length: Integer;
m_jump_table: array[#0..#255] of Integer;
m_jump_value: integer;
m_search_index: Integer;
Constructor create_text_searcher(p_name: String);
procedure initialize_text(p_text_to_search: String);
procedure initialize_pattern_to_search(p_pattern_to_search: String);
function f_index_of: Integer;
function f_found_string(p_pattern_to_search: String): Boolean;
function f_found_string_in_text(p_pattern_to_search,
p_text_to_search: String): Boolean;
Destructor Destroy; Override;
end; // c_text_searcher
| et:
- m_text_to_search est le texte de la page .HTML, m_pattern_to_search la chaîne littérale recherchée dans ce texte
- m_jump_table est une table de saut permettant de progresser lorsque la
chaîne recherchée n'est pas trouvée à un endroit du texte
- initialize_text initialise m_text_to_search
- initialize_pattern_to_search construit la table de saut
- f_index_of fournit la prochaine occurence de la chaîne à partir de m_search_index
Notez que: - toute cette mécanique Boyer Moore Horspool pourait être remplacée par Pos
- l'initialisation de la table de saut n'a besoin d'être effectuée qu'une seule fois, alors que la recherche peut être itérée après chaque recherche ayant réussi
Vous pouvez vous reporter aux articles sur BMH si c'est la technique de recherche qui vous intéresse
3.3 - c_site_searcher
Cette unité est chargée de trouver les fichiers dans le répertoire indiqué, puis de charger le texte et lancer la recherche. La classe est définie par:
c_site_searcher= class(c_basic_object)
m_c_text_searcher: c_text_searcher;
m_c_request_evaluator: c_request_evaluator;
m_case_sensitive: Boolean;
m_search_root: String;
// -- the results are saved here
m_c_result_page_list_ref: c_result_page_list;
Constructor create_site_searcher(p_name: String);
procedure _handle_page(p_path, p_file_name: String);
procedure find_pages(p_path: String; p_case_sensitive: Boolean;
p_c_result_page_list: c_result_page_list);
procedure search_the_site(p_path, p_request: String;
p_case_sensitive: Boolean);
end; // c_site_searcher
| et:
- m_c_text_searcher_ref est la référence vers la classe qui recherche chaque littéral
- m_c_request_evaluator_ref est la mécanique qui évalue l'expression, qui sera présentée ci-dessous
- m_c_result_page_list_ref est le conteneur de la liste de pages correspondant à la recherche
- find_pages est la méthode qui utilise FindFirst et FindNext pour trouver
les pages en appelant _handle_page pour chacune d'entre elles
Le traitement de chaque page est le suivant:
procedure c_site_searcher._handle_page(p_path, p_file_name: String);
const k_content_meta= '<META name="DESCRIPTION" content="';
var l_text_to_search: String;
l_text_length: Integer;
function f_extract_content: String;
var l_start_content, l_index: Integer;
l_content_meta: String;
begin
// -- |<META name="DESCRIPTION" content="last technical papers, ">|
Result:= '';
l_content_meta:= k_content_meta;
if not m_case_sensitive
then l_content_meta:= LowerCase(l_content_meta);
l_start_content:= Pos(l_content_meta, l_text_to_search);
if l_start_content> 0
then begin
// -- skip the meta tag
l_start_content:= l_start_content+ Length(k_content_meta);
l_index:= l_start_content;
while (l_index<= l_text_length) and (l_text_to_search[l_index]<> '"') do
begin
Result:= Result+ l_text_to_search[l_index];
Inc(l_index);
end;
end;
end; // f_extract_content
var l_date_time: tDateTime;
l_c_result_page: c_result_page;
begin // _handle_page
with tStringList.Create do
begin
LoadFromFile(p_path+ p_file_name);
l_text_to_search:= Text;
l_text_length:= Length(l_text_to_search);
if not m_case_sensitive
then l_text_to_search:= LowerCase(l_text_to_search);
m_c_text_searcher.initialize_text(l_text_to_search);
with m_c_request_evaluator do
begin
if f_evaluate_request(m_c_text_searcher)
then begin
// -- fetch the date
if m_c_result_page_list_ref<> Nil
then begin
l_date_time:= f_file_date_time(p_path+ p_file_name);
l_c_result_page:= m_c_result_page_list_ref.f_c_add_result_page('page',
p_path, p_file_name, l_text_length, l_date_time, f_extract_content);
end;
end;
end; // with m_c_request_evaluator
Free;
end; // with tStringList
end; // _handle_page
|
Notez que: - la routine de recherche de page a éliminé (dans notre cas) les pages de "frames html", dans notre cas les pages de gauche et du haut, et qui ne
contiennent aucune information pertinente pour l'utilisateur
- la méthode _handle_page aurait pu être nichée dans find_pages
3.4 - c_cgi_request_evaluator
Cette unité encapsule la classe qui tokenise l'expression, vérifie la syntaxe, et évalue l'expression sur une page donnée. Voici la définition de la classe:
c_request_evaluator= class(c_basic_object)
// -- the original request
m_request: String;
// -- the array of literals
m_c_request_identifiers: tStringList;
m_token_count: Integer;
// -- the array of tokens: negative for NOT AND OR ( )
// -- positive for literals
m_oa_tokens: Array Of Integer;
Constructor create_request_evaluator(p_name: String);
function f_c_self: c_request_evaluator;
function f_tokenize_request(p_request: String): Boolean;
function f_check_syntax: Boolean;
function f_evaluate_request(p_c_text_searcher: c_text_searcher): Boolean;
Destructor Destroy; Override;
end; // c_request_evaluator
|
Nous avons déjà présenté plusieurs évaluateurs sur ce site, et nous ne nous attarderons donc pas à présenter la tokenisation ou la vérification syntaxique. Mais voici comment l'évaluateur lance la recherche de chaque littéral:
function c_request_evaluator.f_evaluate_request(p_c_text_searcher: c_text_searcher): boolean;
type t_symbol_type= Integer;
var // -- the position in the tokenized request
l_token_index: Integer;
// -- the current symbol
l_symbol_type: t_symbol_type;
procedure read_next_symbol;
begin
l_symbol_type:= m_oa_tokens[l_token_index];
Inc(l_token_index);
end; // read_next_symbol
function f_evaluate_expression: Boolean;
function f_evaluate_term: Boolean;
function f_evaluate_factor: Boolean;
var l_identifier: String;
begin
case l_symbol_type of
k_token_opening_parenthesis :
begin
trace_evaluation('parent');
// -- skip (
read_next_symbol;
Result:= f_evaluate_expression;
if l_symbol_type= k_token_closing_parenthesis
then read_next_symbol
else display_evaluation_error('in "(expr)" manque )');
end;
k_token_NOT :
begin
read_next_symbol;
Result:= NOT f_evaluate_factor;
// -- do NOT read next symbol: was read by compile_expression
end;
else
if l_symbol_type>= 0
then begin
l_identifier:= m_c_request_identifiers[l_symbol_type];
// -- look if the symbol is in the text
Result:= p_c_text_searcher.f_found_string(l_identifier);
read_next_symbol;
end
else begin
// -- avoid warnings
Result:= False;
display_evaluation_error('attend fact: k, var, (: '+ IntToStr(l_symbol_type));
end;
end; // case
end; // f_evaluate_factor
begin // f_evaluate_term
Result:= f_evaluate_factor;
while l_symbol_type= k_token_AND do
begin
read_next_symbol;
Result:= Result AND f_evaluate_factor;
end; // while l_symbol_type
end; // f_evaluate_term
begin // f_evaluate_expression
Result:= f_evaluate_term;
while l_symbol_type= k_token_OR do
begin
read_next_symbol;
Result:= Result OR f_evaluate_term;
end; // while
end; // f_evaluate_expression
begin // f_evaluate_request
l_token_index:= 0;
read_next_symbol;
Result:= f_evaluate_expression;
end; // f_evaluate_request
|
Notez que: - le texte de la page a été initialisé une seule fois
- la recherche est lancée dans f_evaluate_factor chaque fois que le facteur est une chaîne littérale
- par rapport au programme de recherche textuelle (non CGI) nous avons légèrement simplifié l'analyse lexicale
3.5 - c_cgi_result_page_list Il s'agit là d'une simple encapsulation des pages correspondant à la recherce, en utilisant une tStringList. Voyez les exemples de squelettes de tStringList sur ce site.
3.6 - c_cgi_html_page_builder Cette classe récupère la liste des pages correspondant à la recherche et construit une page à la syntaxe .HTML.
c_html_result_page_builder=
class(c_basic_object)
// -- m_name: the request (for the error display)
m_c_html_page: tStringList;
m_site_url: String;
Constructor create_html_result_page_builder(p_name: String;
p_site_url: String);
procedure build_error_page(p_error_index, p_error_length: Integer;
p_error_message: String);
procedure build_the_result_page(p_c_result_page_list: c_result_page_list);
Destructor Destroy; Override;
end; // c_html_result_page_builder
| et voici l'exemple (partiel) de construction de page:
procedure c_html_result_page_builder.build_the_result_page(p_c_result_page_list: c_result_page_list);
procedure add_file_name(p_page_index: Integer; p_c_result_page: c_result_page);
begin
// ...
end; // add_file_name
procedure add_bottom_links;
begin
// ...
end; // add_bottom_links
var l_element_index: Integer;
l_number_of_files: String;
begin // build_result_page
m_c_html_page:= tStringList.Create;
with p_c_result_page_list do
l_number_of_files:= '(trouvé '+ IntToStr(f_result_page_count)+ ' sur '
+ IntToStr(m_total_page_count)+ ' pages)';
with m_c_html_page do
begin
Add('<HTML>');
Add(' <HEAD>');
Add(' <TITLE>Résultats</TITLE>');
Add(' </HEAD>');
Add(' <BODY>');
Add(' <H2><CENTER><FONT COLOR="#FF0000">'+ m_name
+ '</FONT><BR>'
+ l_number_of_files+ '</CENTER></H2>');
with p_c_result_page_list do
for l_element_index:= 0 to f_result_page_count- 1 do
add_file_name(l_element_index, f_c_result_page(l_element_index));
add_bottom_links;
Add(' </BODY>');
Add('</HTML>');
end; // with m_c_html_page
end; // build_the_result_page
|
3.7 - u_cgi_coliget_search
L'ensemble des classes est utilisé par l'unité principale, qui contient une seule procédure qui gère l'ensemble: - lecture et analyse de la requête reçue de serveur
- tokenisation et vérification de la requête
- chargement et analyse de chaque page, avec construction de la liste des pages correctes
- construction de la page résultat HTML
- envoi de la page résultat vers le serveur
Voici la procédure unique:
procedure do_search(p_write_segment,
p_log_name, p_form_search_root_log_prefix_name,
p_site_url: String);
// ...
var l_request: String;
l_c_html_result_page_builder: c_html_result_page_builder;
begin // do_search
// -- get the request without % etc
analyze_form_values(l_request, g_case_sensitive);
if not g_case_sensitive
then l_request:= LowerCase(l_request);
l_c_html_result_page_builder:=
c_html_result_page_builder.create_html_result_page_builder(l_request,
p_site_url);
// -- build the target file list
evaluate_request(l_request);
send_answer(g_output_name);
l_c_html_result_page_builder.Free;
end; // do_search
|
L'analyze de la chaîne à la syntaxe CGI est réalisée ainsi:
procedure analyze_form_values(var pv_request: String; var pv_case_sensitive: Boolean);
function f_convert_cgi_question_string(p_cgi_string: String): String;
// -- convert "q=uml&minuscule=on&
begin
// ...
end; // f_convert_cgi_question_string
var l_raw_request_string: String;
l_minuscule_position: Integer;
l_minuscule_string: String;
begin // analyze_form_values
with c_form.create_form('forms', f_cgi_exe_path
+ p_write_segment+ p_form_search_root_log_prefix_name) do
begin
get_form_result;
l_raw_request_string:= m_raw_answer_string;
pv_request:= f_convert_cgi_question_string(l_raw_request_string);
l_minuscule_position:= Pos('minuscule', pv_request);
if l_minuscule_position> 0
then begin
// -- the end of the string
l_minuscule_string:= Copy(pv_request, l_minuscule_position,
Length(pv_request)+ 1- l_minuscule_position);
pv_case_sensitive:= Pos('=on', l_minuscule_string)<= 0;
pv_request:= Trim(Copy(pv_request, 1, l_minuscule_position- 1));
end
else pv_case_sensitive:= True;
Free;
end; // with c_form.create_form
end; // analyze_form_values
| où get_form_result est la routine que nous avons déjà présentée dans
le tutorial CGI
Et la procédure qui lance les test:
procedure evaluate_request(p_request: String);
var l_c_result_page_list: c_result_page_list;
l_search_path: String;
begin
with c_site_searcher.create_site_searcher('search') do
begin
if m_c_request_evaluator.f_tokenize_request(p_request)
then begin
// -- check the syntax
if m_c_request_evaluator.f_check_syntax
then begin
l_c_result_page_list:= c_result_page_list.create_result_page_list('page_list');
if f_is_debug
then l_search_path:= g_debug_search_path
else begin
l_search_path:= f_cgi_exe_path;
// -- remove scripts
l_search_path:= f_remove_end_if_end_is_equal_to(Lowercase(l_search_path), 'scripts\');
end;
find_pages(l_search_path, g_case_sensitive, l_c_result_page_list);
// -- now use the page list to build the answer
l_c_html_result_page_builder.build_the_result_page(l_c_result_page_list);
l_c_result_page_list.Free;
end
else begin
// -- build the syntax error answer
with m_c_request_evaluator do
l_c_html_result_page_builder.build_error_page(m_error_index,
m_error_length, m_error_message);
end;
end
else begin
// -- build the lexical error answer
with m_c_request_evaluator do
l_c_html_result_page_builder.build_error_page(m_error_index,
m_error_length, m_error_message);
end;
Free;
end; // with c_site_searcher
end; // evaluate_request
|
3.8 - Test du CGI Le test d'un programme CGI est assez délicat: - il faut disposer d'un serveur Web
- les messages de mise au point ne peuvent être affichés sur une Forme, car
le programme travaille en mode console
Pour le serveur Web: - une première solution est de construire un petit serveur en Delphi. Un tel "serveur", qui ne fait qu'utiliser des tSocket pour implémenter le
protocole HTTP, avait été présenté dans Pascalissime. Nous avions utilisé une version voisine pour nos essais SOAP.
L'inconvénient est que nous pourrons toujours ajuster le serveur et le
client pour qu'ils collaborent correctement, mais les véritables serveurs ont leur volonté propre, et de ce fait, nos test ne sont peut-être pas réalistes - Dans notre précédent article, nous avions utilisé le serveur personnel
Windows (PWS) pour notre mise au point. C'est une possibilité
- plusieurs serveurs ont été fournis par Borland ou d'autres développeurs Delphi. Le fait que Borland ne propose pas de serveur souligne le fait que
l'émulation d'Internet Server ou d'Apache n'est pas trivial
- nous pouvons utiliser le serveur de notre Provider, et tester sur son serveur. Avec les vitesses et les coûts actuels d'ADSL, c'est la solution
que nous avons choisi: nous mettons au point le programme pour qu'il compile et fonctionne raisonablement en mode "non-cgi", et nous testons la partie CGI sur le véritable serveur
Quels sont alors les test à effectuer avant le placer le CGI sur le serveur ? Eh bien - nous vérifions que les unités sont cohérentes
- nous effectuons des essais sans la partie entrée (lecture de la requête CGI)
et sans la partie sortie (émission de la page Web)
Le premier test consiste simplement à tester la partie qui analyze la requête, charge les pages, et construit une liste de pages correspondant aux pages correctes.
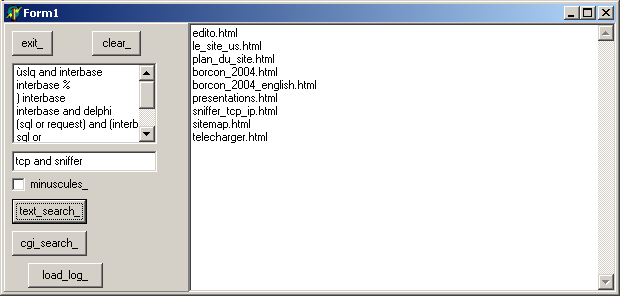
Voici un exemple de test de la partie recherche pure:
procedure TForm1.text_search_Click(Sender: TObject);
begin
with c_site_searcher.create_site_searcher('search') do
begin
search_the_site(k_path, Edit1.Text,
not Form1.minuscules_.Checked);
Form1.Memo1.Lines.Assign(m_c_ok_file_list);
Free;
end; // with c_site_searcher
end; // text_search_Click
| dont voici un exemple d'utilisation:
Le second test est effectué Voici la méthode d'appel:
procedure TForm1.text_search_Click(Sender: TObject);
begin
with c_site_searcher.create_site_searcher('search') do
begin
search_the_site(k_path, Edit1.Text,
not Form1.minuscules_.Checked);
Form1.Memo1.Lines.Assign(m_c_ok_file_list);
Free;
end; // with c_site_searcher
end; // text_search_Click
| Cette procédure n'affiche rien (par construction), mais crée un page dans le
répertoire de l'EXE et remplit un fichier log, si nous en avons créé un. C'est bien le cas, et le bouton "load_log" permet de visualiser les étapes clé de la recherche. Voici un exemple:
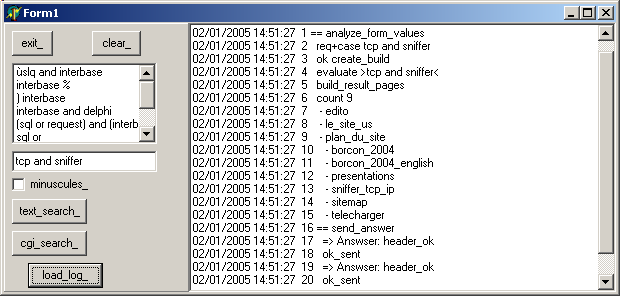 Notez que c'est le même journal qui sera déposé dans un fichier chez notre hébergeur et qui permettra la vérification du bon fonctionnement en mode distant.
Le véritable programme principal du CGI est le suivant:
procedure TForm1.text_search_Click(Sender: TObject);
begin
with c_site_searcher.create_site_searcher('search') do
begin
search_the_site(k_path, Edit1.Text,
not Form1.minuscules_.Checked);
Form1.Memo1.Lines.Assign(m_c_ok_file_list);
Free;
end; // with c_site_searcher
end; // text_search_Click
| Et vous constaterez qu'il utilise bien la même méthode que le programme de test.
4 - Améliorations Parmi les améliorations qui peuvent être apportées: - utiliser un algorithme de recherche de plusieurs chaînes à la fois (Teuhola Raita de mémoire)
- au niveau de résultat présenter les mots clés et quelques mots les entourant (KWIC: keyword in context), plutôt que de présenter le résumé de nos pages
- la recherche intégrale de toutes les pages de notre site peut sembler
excessive. Notre précédente version utilisait une liste de mots "pertinents", mais obligeait à construire manuellement cette liste pour chaque page. Nos pages contiennent obligatoirement le résumé et les
mots-clé, mais en plus il faillait construire cette liste supplémentaire. Une solution intermédiaire serait la construction d'un "thésaurus pertinent" par page: une liste de tous les mots en supprimant les mots triviaux (le la begin etc)
Actuellement, la recherche notre site contient une centaine de pages, et le volume recherché est de l'ordre de l'ordre de 2 megas. La première recherche sur notre PC (1.400MHz et 256 Meg de mémoire) est de l'ordre de 5 à 10
secondes. Les recherches suivantes sont beaucoup plus rapides à cause des caches.
5 - Télécharger les sources Pour télécharger, cliquez:
Les .ZIP comprennent:
- le .DPR, la forme principale, les formes annexes eventuelles
- les fichiers de paramètres (le schéma et le batch de création)
- dans chaque .ZIP, toutes les librairies nécessaires à chaque projet (chaque .ZIP est autonaume)
Ces .ZIP contiennent des chemins RELATIFS. Par conséquent: - créez un répertoire n'importe où sur votre machine
- placez le .ZIP dans ce répertoire
- dézippez et les sous-répertoires nécessaires seront créés
- compilez et exécutez
Ces .ZIP ne modifient pas votre PC (pas de changement de la Base de Registre, de DLL ou autre). Pour supprimer le projet, effacez le répertoire.
Comme d'habitude:
- nous vous remercions de nous signaler toute erreur, inexactitude ou problème de téléchargement en envoyant un e-mail à jcolibri@jcolibri.com. Les corrections
qui en résulteront pourront aider les prochains lecteurs
- tous vos commentaires, remarques, questions, critiques, suggestion d'article, ou mentions d'autres sources sur le même sujet seront de même
les bienvenus à jcolibri@jcolibri.com.
- plus simplement, vous pouvez taper (anonymement ou en fournissant votre e-mail pour une réponse) vos commentaires ci-dessus et nous les envoyer en
cliquant "envoyer" :
- et si vous avez apprécié cet article, faites connaître notre site,
ajoutez un lien dans vos listes de liens ou citez-nous dans vos blogs ou réponses sur les messageries. C'est très simple: plus nous aurons de visiteurs et de références Google, plus nous écrirons d'articles.
6 - Références
7 - L'auteur John COLIBRI est passionné par le développement Delphi et les applications de Bases de Données. Il a écrit de nombreux livres et articles, et partage son temps entre le développement de projets (nouveaux projets, maintenance, audit, migration BDE, migration Xe_n, refactoring) pour ses clients, le
conseil (composants, architecture, test) et la
formation. Son site contient des articles
avec code source, ainsi que le programme et le calendrier des stages de formation Delphi, base de données, programmation objet, Services Web, Tcp/Ip et
UML qu'il anime personellement tous les mois, à Paris, en province ou sur site client.
|